
“LLM-generated passwords…appear strong, but are fundamentally insecure, because LLMs are designed to predict tokens – the opposite of securely and uniformly sampling random characters.”
In July, I will run another live edition of CODE100 at the WeAreDevelopers World Congress and if you want to take part and earn your spot on stage in front of 5000 people, why not have a go at solving this year’s challenge?
The char explosion problem
Oh dear, we wanted to show you some data insights about the WeAreDevelopers World Congress speaker submissions, but things went very wrong and our bar charts exploded …

Now we call on all you coders, hackers and developers out there to help us recover the data we wanted to show.
Each bar of the chart has been rotated, moved to a different part of the screen and scaled.
We were able to analyse the location and other data though. For each bar chart you get the `x` and `y` screen coordinate where its bounding box starts, the angle of the `Rotation` in radians, the `scale` as a factor of 1 and the `width` and `height` in pixels.
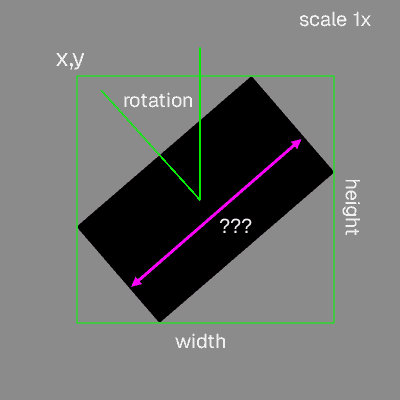
All the data you need is in dataset.csv in the format of comma separated values.
Item,Group,x,y,Width,Height,Rotation,Scale
JavaScript,Languages,239.97,391.67,56.71,29.15,0.28,0.76
Python,Languages,401.44,353.55,59.43,43.76,0.54,0.77
Now, what we want you to use your coding skills for is to find the widths of the bars…
Can you tell us:
- What bar is the biggest?
- What bar is the smallest?
- What are the averages of each chart (Languages, Tools, Categories, AI topics)?
For example (no, not the real data):
Biggest item is JavaScript with 14
Smallest item is Cobol with 2
Averages: – Languages: 30 – Tools: 23 – Categories: 78 – AI topics: 12
Do you have your results? Then why not apply as a Challenger for the CODE100 in July ?



Technologies of preserving and reviving organisms are already redefining the meaning of life, death, and extinction itself
- by Sadiah Qureshi
Instant coffee seems unremarkable. It’s just powder and hot water. But making it work took decades.
In 2023, the Swedish government announced that the country’s schools would be going back to basics, emphasizing skills such as reading and writing, particularly in early grades. After mostly being sidelined, physical books are now being reintroduced into classrooms, and students are learning to write the old-fashioned way: by hand, with a pencil or pen, on sheets of paper. The Swedish government also plans to make schools cellphone-free throughout the country.
Educational authorities have been investing heavily. Last year alone, the education ministry allocated $83 million to purchase textbooks and teachers’ guides. In a country with about 11 million people, the aim is for every student to have a physical textbook for each subject. The government also put $54 million towards the purchase of fiction and non-fiction books for students.
These moves represent a dramatic pivot from previous decades, during which Sweden—and many other nations—moved away from physical books in favor of tablets and digital resources in an effort to prepare students for life in an online world. Perhaps unsurprisingly, the Nordic country’s efforts have sparked a debate on the role of digital technology in education, one that extends well beyond the country’s borders. US parents in districts that have adopted digital technology to a great extent may be wondering if educators will reverse course, too.


Lately, there’s been a spate of revelations about AI users slipping slop-assisted work past human editors.
First there was Shy Girl, the horror novel pulled by its publisher once they realized it had been largely AI-generated. Editors failed to see the slop, and many readers were duped too. Emily Hughes, author of Horror for Weenies, published an excellent reflection on the deeper issues at play, as well as the personal embarrassment of falling for it. But it’s likely now that all of us have been tricked at some point, and it’s not just because the software is improving. As Hughes wrote, “remember that LLMs write like that because people write like that.” In other words, the slop is coming from inside the house.
Then there was more discourse around Washington Post columnist Megan McArdle’s admission on X that she frequently leans on AI software in her writing process. McArdle’s usage struck many (myself included) as being well beyond what’s acceptable for a professional writer. AI has been integrated into so many digital processes that keeping writing completely clean may be actually impossible. And even AI skeptics will give a pass to using software for some of our most thankless chores. But McArdle goes much farther than this, using digital tools to “generate pushback on my column thesis, suggest trims when I’m over my word count, sharpen podcast interview questions, and perform a final fact check on columns and editorials.” She claims this doesn’t interfere with “the main job: reading, thinking, and writing,” but I think it’s reasonable to counter that each and every step of reading, drafting, and rewriting constitutes thinking—writing is thinking, and allowing generative software to take over any part of the writing process compromises it. I imagine The Washington Post won’t think of this as an issue, though, since both McArdle and the Post have been frequent AI boosters.
And just the other day, The New York Times announced they’ll no longer be working with the freelancer Alex Preston after he was caught using an LLM to write a book review, according to The Wrap. After a reader flagged that Preston’s writing copied language from a Guardian review, Preston “admitted he used an AI tool to help draft the piece and that he failed to catch the Guardian material before the paper published the review.” The Times‘s staff also missed it.
In each of these cases, a tech company outsmarted a human—or several—either by producing text convincing enough to pass the smell test, or by creating and marketing a service that convinced a writer to offload part of their labor. The way out of this bind is going to require all of us to get better at spotting the output of AI, and to continue shaming those who get caught red keyboarded.
I’ll admit I may overestimate my own abilities to spot AI writing, because so many of my interactions with the technology have been so underwhelming. Even AI-powered search—which is what I hear users and apologists tout most often—isn’t good at all. As an experiment, and to get a sense of what other people might be hearing about me from LLMs, I asked Gemini this simple question: “Who is James Folta?” The answers it spit out were staggeringly wrong. I tried multiple times with different phrasings, and each time there were major mistakes. The broad strokes were usually close, and the AI flattered me as a “thought leader” or “a prominent writer,” but the model ignored my personal website, hallucinated articles, incorrectly attributed other people’s writing to me, and completely omitted any of my work for Lit Hub. (Interestingly, it did pay a lot of attention to one thing: “James Folta’s take on AI is one of sharp, vocal criticism, particularly regarding its impact on creativity, media literacy, and human labor … he has written extensively about the “degrading” effects of generative Al on the internet and the arts.” That’s right, and I’ll keep arguing with the robots.)
I bring this up because the solution I so often hear is to counter AI with other software that can sniff it out, a loopy arms race that reminds me of the Simpsons gag about “a fabulous type of gorilla that thrives on snake meat.” But of course these detection programs are also unreliable, and perhaps will never get any better. Frustratingly, all of this back and forth, parry and riposte between AIs and anti-AIs will only further entrench these systems and enrich tech companies by making us beholden to them on either side of the debate.
I have to trust that if we get to together and get organized, we can find ways to push back. I’ve been part of some exciting conversations with peers about how to advocate for ourselves and our work, and I’ve been inspired by unions and other labor groups who are organizing and agitating against AI overreach. As always, solidarity is the way.
But in the meantime, if overworked editors don’t have the time to check every piece of writing, and if squeezed freelancers are turning to desperate tools to make a living, and if digital correctives are unreliable, we’re in a tough place.
Next Page of Stories