For The Paris Review, Grace Byron recounts how her obsession with horseshoe crabs began with a visit to the Jamaica Bay Wildlife Refuge to spot birds. Her interest veers from curiosity into conservation when she and a couple of friends volunteer for a horseshoe monitoring session with the NYC Bird Alliance. There, they helped log and tag horseshoe crabs emerging from the water at high tide to mate on Plumb Beach.
Agnes and Ashe waited behind, picking up trash as Ann gave us the outline of our night. She kept checking her watch, waiting for the precise moment of high tide: 7:29 P.M. Using two white pipes connected into a square, we prepared to survey the number of horseshoe crabs present that night at random. The pace at which we had to stop and check for critters was a bizarre math problem that I couldn’t quite follow. Meanwhile, two volunteers carried clipboards to note the number of horseshoe crabs in the sample field. I looked around. So far there weren’t so many. As requested, we looked around and grabbed the numbers of those already tagged.
Imagine that someone gives you a list of five numbers: 1, 6, 21, 107 and — wait for it — 47,176,870. Can you guess what comes next? If you’re stumped, you’re not alone. These are the first five busy beaver numbers. They form a sequence that’s intimately tied to one of the most notoriously difficult questions in theoretical computer science. Determining the values of busy beaver numbers is a…
Oops! I did it again. I went viral for looking for love, and now millions of people know I have zero bitches, and CNN contacted me about it. Only this time, the whole gang is in it together.
It all started when my friends were lamenting about not having girlfriends, and I jokingly offered to find them ones via flyer (I am notorious for flyering for my schemes, e.g. for Sit Club, an anti-run club, and Strippers for Charity, a charity gala). But my friends were actually interested, and so dear reader, we embarked on our quest to find love.
subscribe to 𝓇𝒶𝓌 & 𝒻𝑒𝓇𝒶𝓁 to support the arts
I took inspiration from the “personals” section of vintage newspapers and made a website sfpersonals.com.
examples of the “personals” section of old newspapers
Then I gathered my most eligible single friends at my office hours ($1 margarita night), pitched the idea, and interviewed them. (You may already be familiar with my investigative journalism if you went to Tam High in 2017, where I was the newspaper’s Editor-in-Chief. Go Hawks!)
I wrote about each friend like a character you could easily imagine in your mind - colorful, extremely specific, and low-key roasting them.
my website!
I also described their ideal partner as a character you can imagine in your head, figuring this would make readers who resonate even more interested, and maybe make readers think of a friend who had those qualities, so they’d forward it along. Each bachelor/bachelorette also had a key question they asked their admirers, to help them vet contenders.
I figured that to reach the right people, this would have to go viral, so it’d have to be funny and entertaining to everyone, not just people looking for a relationship.
I added a crossword, because newspapers have crosswords. Also, if you don’t like hot singles, then you probably like crosswords, and that’s how I’d capture the whole market.
you either like hot singles, or crosswords, or both!
I included some extremely unhelpful FAQs, based not on actual frequently asked questions, but on questions I preemptively thought would be funny to answer.
questions, though not necessarily those of the “frequently asked” kind
And yes, I did put myself on the site, because I am a diligent Product Mommy who dogfoods her product (and I may or may not have ulterior motives).
I also made my friends promise that if I find their future spouses, I get to officiate their wedding. You see, three years ago I became a licensed Reverend because it’s fun and easy to do, and every year since, I’ve received an email congratulating me on another year of being a Reverend, unknowingly relentlessly taunting me for still having yet to officiate a wedding. This weighs on me greatly.
they taunt me!
Here’s the thing: dating apps are counter-incentivized, they earn money by keeping you single. However, my incentives are aligned, I want to find my friends partners so that I get to officiate their weddings. My Certificate of Ministry is burning a hole in my pocket.
Finally, to advertise my sexy singles, I put flyers up around San Francisco.
dating flyers!
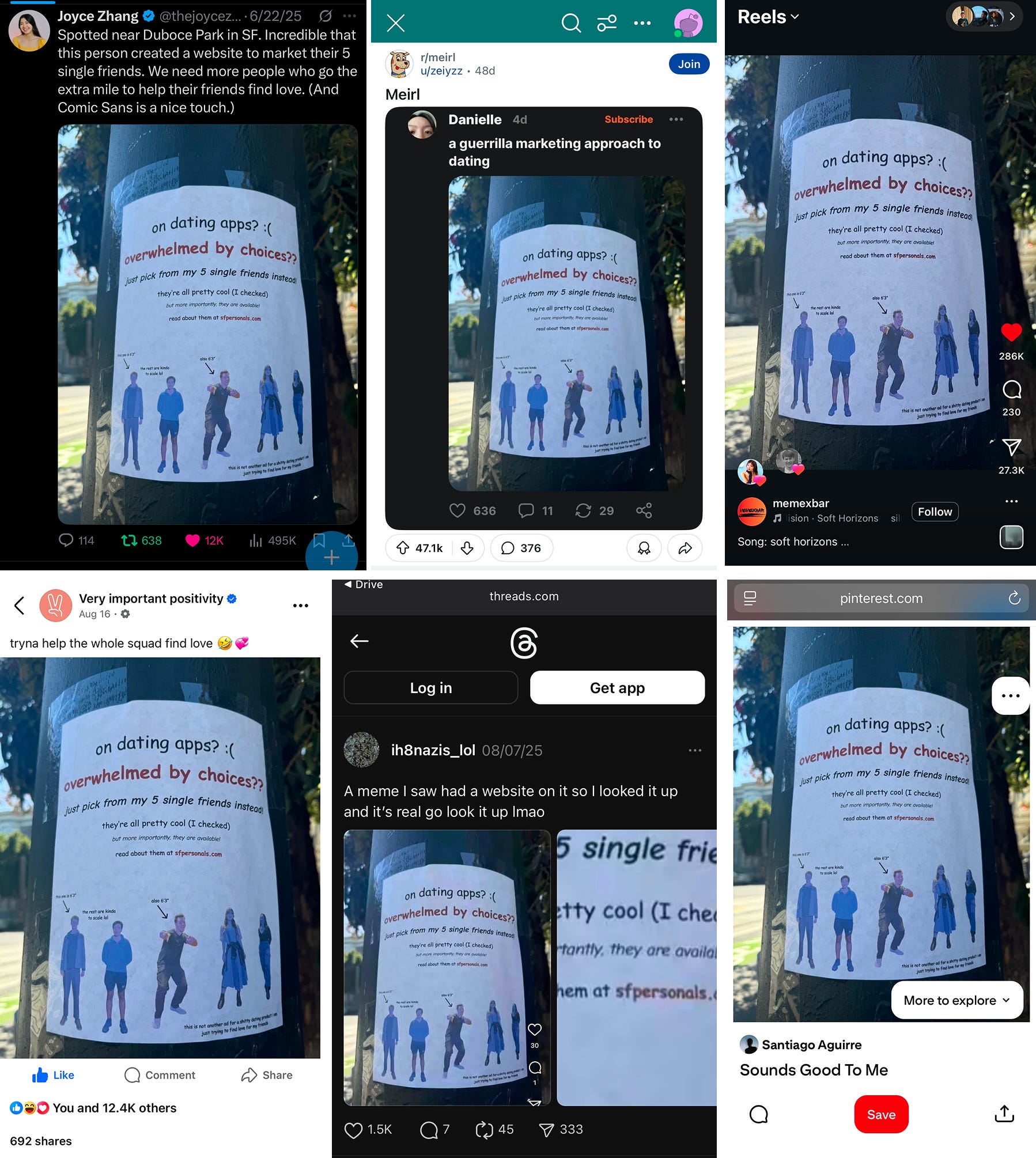
Within 24 hours, a dating coach posted a picture on Twitter, and it blew up. Then it went viral on Substack, Reddit’s r/sanfrancisco, on the literal front page of Reddit itself, Reels, Facebook, Threads, even Pinterest???
sfpersonals.com transversing across the internet
It amassed millions of views, hundreds of thousands of likes, and 600+ people emailed in to date my friends.
The emails were extremely funny.
Thousands of people thought Anna and Will should date. The comments section of every post was filled with it, and people wrote long, elaborate theories on why they weren’t already dating, devising fan-fiction basically. Dozens of people emailed just to say they should date, and someone even wrote a multi-paragraph essay about it. Because of this, Anna and Will went on a date. I heard it went alright.
Cougars loved Alex and he discovered that the feelings were mutual. And so he increased his age range.
People fucked heavy with the crossword. They would email me just to ask if they completed the crossword correctly.
Anna has two exes and they’re both Chinese and named Kevin. I told her, “Anna, you just haven’t met the right Chinese Kevin yet.” Then a man wrote in who met exactly what Anna was asking for, and was Chinese and named Kevin. Her soulmate, I think.
Someone sent the most condescending but well-meaning email titled: “Anna is autistic and that’s wonderful.” Also, someone armchair diagnosed Will with Marfan’s Syndrome. None of you people are doctors, what are you even talking about.
A women wrote that she was happily partnered, however, she did want to share a multi-page self-insert story of her rescuing Mehran from prison.
Four separate men answered my question (“how will you support my projects like Strippers for Charity”) by saying they’d MC the event?? Like some guys will really read “how will you support my hard work” and reply, “well I’ll take over as the star of the show.”
Multiple people made LinkedIn accounts just to apply to date us (I should really be getting a commission here).
A group of high schoolers saw me in the wild putting up posters and asked to take a photo with me (I guess this is how celebrities feel??)
Two chaotic bisexual queens offered to date any of us.
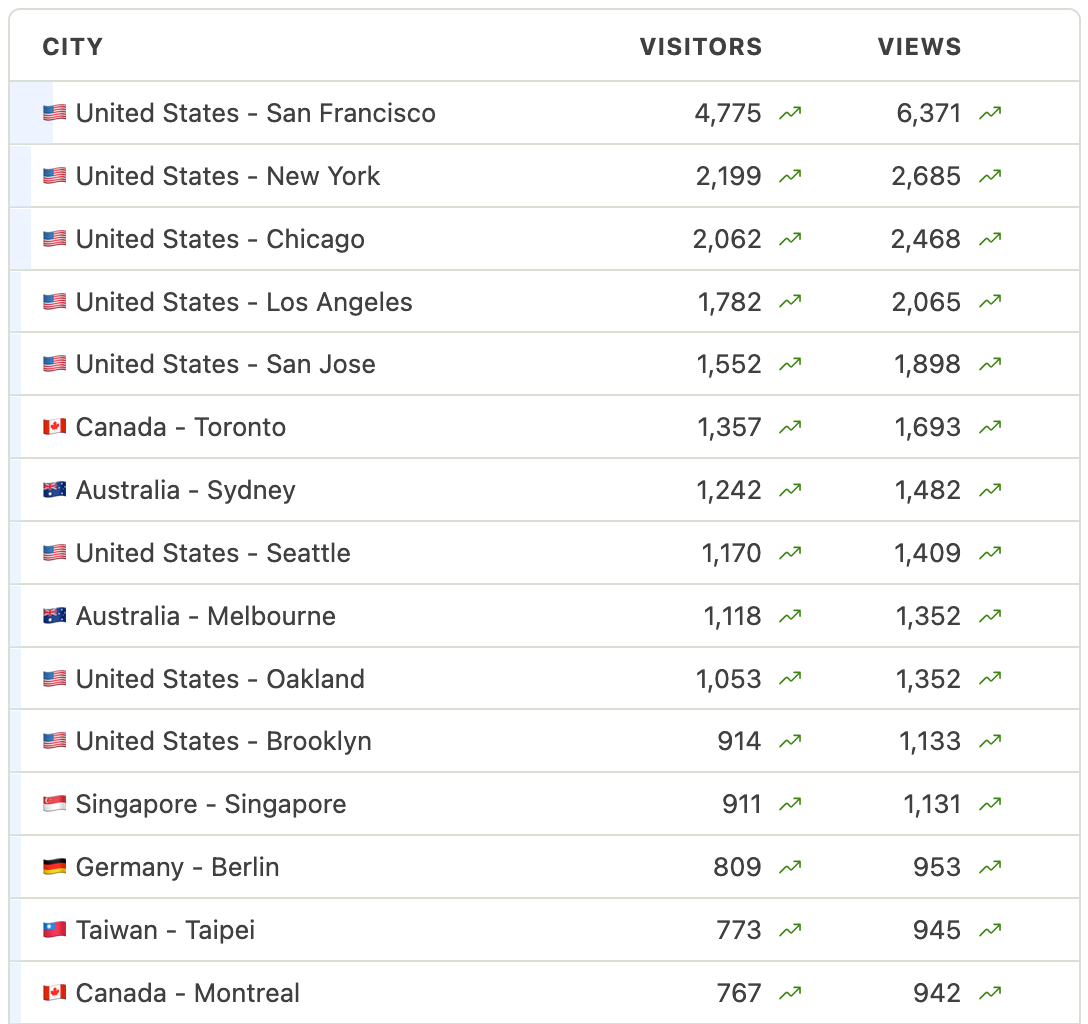
The scheme went viral internationally, gaining traction in some really random places. Why were people in Taiwan reading this. Who are these people.
some stats for you data nerds
Only ~5k (3.6% of) people who visited the site actually lived in San Francisco. No, the “SF” in “sfpersonals” does not stand for “single friends,” as one commenter thought.
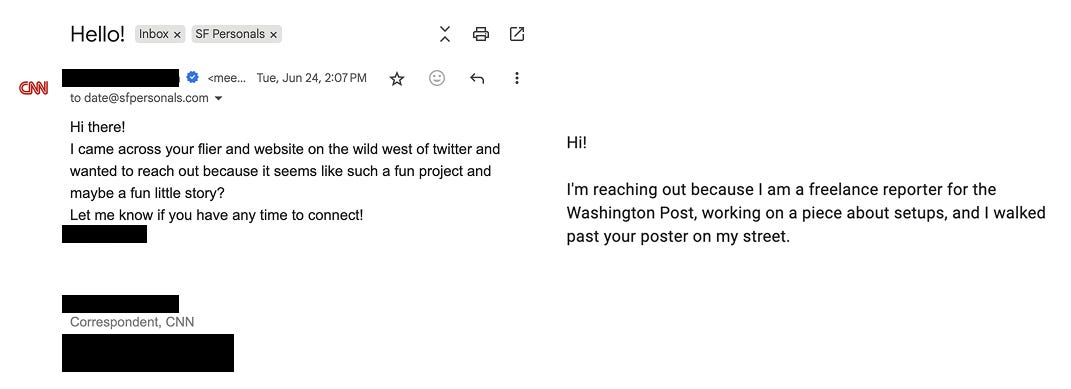
And The Media once again slid into my DMs.
hehehehe
I was also invited to present this project at Demos & Chill! And my friends went on dates with their admirers, but those are not my stories to share.
So. Ultimately, did this work?
No.
But neither do most relationships! Also, it’s important to remember that 50% of marriages end in divorce anyway. Maybe the real relationship was the clout we gained along the way.
To be serious though, it’s only been two months since I launched this and many prospects are still in the pipeline. Plus it keeps randomly blowing up, so it’s possible the right people just haven’t seen it yet. If a marriage does come from this, I’ll make sure my dear 𝓇𝒶𝓌 & 𝒻𝑒𝓇𝒶𝓁 readers are the first to know.
I have some more personal reflections about this project, but that’s so cringe, so I’m hiding them behind the paywall like a coward. An entrepreneurial coward. If you wanna be nosy, there’s a price to pay ($6.90).
Thanks for reading my blog, love ya!
subscribe to 𝓇𝒶𝓌 and 𝒻𝑒𝓇𝒶𝓁 to support the arts, and because it’s the right thing to do
P.S. Read about my other dating-related scheme, the time I made a survey for guys who want to date me (as a joke) but after 400+ responses, I felt an obligation to the scientific community to write a research paper. And then Substack featured it in their Weekender.
P.P.S. If you’re a loyal 𝓇𝒶𝓌 & 𝒻𝑒𝓇𝒶𝓁 reader, you may recognize Cool Alex from the SF Personals site, as we met him through our Alextravaganza (Alex-themed party we threw).
Big O notation is a way of describing the performance of a function without
using time. Rather than timing a function from start to finish, big O describes
how the time grows as the input size increases. It is used to help understand
how programs will perform across a range of inputs.
In this post I'm going to cover 4 frequently-used categories of big O notation:
constant, logarithmic, linear, and quadratic. Don't worry if
these words mean nothing to you right now. I'm going to talk about them in
detail, as well as visualise them, throughout this post.
Before you scroll! This post has been sponsored by the wonderful folks at ittybit, and their API for working
with videos, images, and audio. If you need to store, encode, or get
intelligence from the media files in your app, check them out!
I'm going to pass in 1 billion, written using the shorthand 1e9, so it takes a
noticeable amount of time to run. Press the button below to
measure how long it takes to calculate the sum of 1 to 1 billion.
function sum(n) {
let total = 0;
for (let i = 1; i <= n; i++) {
total += i;
}
return total;
}
const result = sum(1e9);
On my laptop this takes just under 1 second. The time you get may be different,
and it may vary by a few tens of milliseconds each time you run it. This is
expected.
Timing code this way, by taking the start time and the end time and finding the
difference, is called wall-clock time.
How long do you think 2 billion, 2e9, will take?
function sum(n) {
let total = 0;
for (let i = 1; i <= n; i++) {
total += i;
}
return total;
}
const result = sum(2e9);
It takes about twice as long. The code loops n times and does a single
addition each time. If we passed in 3 billion, we would expect the execution
time to increase by a factor of three.
The relationship between a function's input and how long it takes to execute
is called its time complexity, and big O notation is how we
communicate what the time complexity of a function is.
Play around with the buttons below. Each bar adds an extra 1 billion to the n
that we pass to sum, so the 1e9 button calls sum(1e9),
the 2e9 button calls sum(2e9), and so on. You should see
2e9 take about twice as long as 1e9, and 3e9 take about three times as
long as 1e9.
function sum(n) {
let total = 0;
for (let i = 1; i <= n; i++) {
total += i;
}
return total;
}
sum(1e9);
sum(2e9);
sum(3e9);
sum(4e9);
sum(5e9);
Because sum's wall-clock time grows at the same rate as n, e.g. sum(20)
would take twice as long as sum(10), we say that sum is a "linear"
function. It has a big O of n, or O(n).
Why do we use that syntax: O(n)? What is O? Why those brackets?
The "O" stands for "order," short for "order of growth." Said out loud it would
be: "the order of growth of the sum function is n." O(n) is a compact way
to write that. The notation was created by the German mathematician Paul
Bachmann in 1894. Also, the "O" (letter) might look like a 0 (number) in some
typefaces. It is always the letter O.
A different way to sum the numbers from 1 to n is to use the formula (n*(n+1))/2. Carl Friedrich Gauss discovered this formula in the early 1800s, and
it's a clever way for us to avoid having to loop over all of the numbers.
Here's the result of this formula with the numbers from 1 to 5. In each case
the result should be the same as doing, e.g. 1+2+3+4+5 for n=5.
(1*2)/2 = 2/2 = 1
(2*3)/2 = 6/2 = 3
(3*4)/2 = 12/2 = 6
(4*5)/2 = 20/2 = 10
(5*6)/2 = 30/2 = 15
Here's how sum would look if it used that formula instead of the loop we had
before:
functionsum(n){return(n*(n+1))/2;}
How do you think the wall-clock time of this function changes as n increases?
The next two examples differ by a factor of 100.
function sum(n) {
return (n * (n + 1)) / 2;
}
const result = sum(1e9);
function sum(n) {
return (n * (n + 1)) / 2;
}
const result = sum(100e9);
This example isn't broken. Both of these functions take almost no time to at
all. The variance in timing is caused by the browser, and the unpredictability
of computers, not the sum function. Running each example a few times, you
should see that the wall-clock time hovers around the same value for both.
We call functions like this, whose wall-clock time is about the same no matter
what input you give it, constant or O(1).
Wow, so we improved our sum function from O(n) to O(1)! It
always runs instantly now!
We did! Though it is crucial to remember that O(1) doesn't always mean
"instant." It means that the time taken doesn't increase with the size
of the input. In the case of our new sum function, it's more or less
instant. But it's possible for an O(1) algorithm to take several minutes or
even hours, depending on what it does.
It's also possible for an O(n) algorithm to be faster than an O(1)
algorithm for some of its inputs. Eventually, though, the O(1) algorithm
will outpace the O(n) algorithm as the input size grows. Play with the
slider below to see an example of that.