
Months ago, I saw a post titled “Rejected from DS Role with no feedback” on Reddit’s Data Science subreddit, in which a prospective job candidate for a data science position provided a Colab Notebook documenting their submission for a take-home assignment and asking for feedback as to why they were rejected. Per the Reddit user, the assignment was:
Use the publicly available IMDB Datasets to build a model that predicts a movie’s average rating. Please document your approach and present your results in the notebook. Make sure your code is well-organized so that we can follow your modeling process.
IMDb, the Internet Movie Database owned by Amazon, allows users to rate movies on a scale from 1 to 10, wherein the average rating is then displayed prominently on the movie’s page:

The Shawshank Redemption is currently the highest-rated movie on IMDb with an average rating of 9.3 derived from 3.1 million user votes.
In their notebook, the Redditor identifies a few intuitive features for such a model, including the year in which the movie was released, the genre(s) of the movies, and the actors/directors of the movie. However, the model they built is a TensorFlow and Keras-based neural network, with all the bells-and-whistles such as batch normalization and dropout. The immediate response by other data scientists on /r/datascience was, at its most polite, “why did you use a neural network when it’s a black box that you can’t explain?”
Reading those replies made me nostalgic. Way back in 2017, before my first job as a data scientist, neural networks using frameworks such as TensorFlow and Keras were all the rage for their ability to “solve any problem” but were often seen as lazy and unskilled compared to traditional statistical modeling such as ordinary least squares linear regression or even gradient boosted trees. Although it’s funny to see that perception against neural networks in the data science community hasn’t changed since, nowadays the black box nature of neural networks can be an acceptable business tradeoff if the prediction results are higher quality and interpretability is not required.
Looking back at the assignment description, the objective is only “predict a movie’s average rating.” For data science interview take-homes, this is unusual: those assignments typically have an extra instruction along the lines of “explain your model and what decisions stakeholders should make as a result of it”, which is a strong hint that you need to use an explainable model like linear regression to obtain feature coefficients, or even a middle-ground like gradient boosted trees and its variable importance to quantify relative feature contribution to the model. 1 In absence of that particular constraint, it’s arguable that anything goes, including neural networks.
The quality of neural networks have improved significantly since 2017, even moreso due to the massive rise of LLMs. Why not try just feeding a LLM all raw metadata for a movie and encode it into a text embedding and build a statistical model based off of that? Would a neural network do better than a traditional statistical model in that instance? Let’s find out!
About IMDb Data
The IMDb Non-Commercial Datasets are famous sets of data that have been around for nearly a decade 2 but are still updated daily. Back in 2018 as a budding data scientist, I performed a fun exporatory data analysis using these datasets, although the results aren’t too surprising.

The average rating for a movie is around 6 and tends to skew higher: a common trend in internet rating systems.
But in truth, these datasets are a terrible idea for companies to use for a take-home assignment. Although the datasets are released under a non-commercial license, IMDb doesn’t want to give too much information to their competitors, which results in a severely limited amount of features that could be used to build a good predictive model. Here are the common movie-performance-related features present in the title.basics.tsv.gz file:
- tconst: unique identifier of the title
- titleType: the type/format of the title (e.g. movie, tvmovie, short, tvseries, etc)
- primaryTitle: the more popular title / the title used by the filmmakers on promotional materials at the point of release
- isAdult: 0: non-adult title; 1: adult title
- startYear: represents the release year of a title.
- runtimeMinutes: primary runtime of the title, in minutes
- genres: includes up to three genres associated with the title
This is a sensible schema for describing a movie, although it lacks some important information that would be very useful to determine movie quality such as production company, summary blurbs, granular genres/tags, and plot/setting — all of which are available on the IMDb movie page itself and presumably accessible through the paid API. Of note, since the assignment explicitly asks for a movie’s average rating, we need to filter the data to only movie and tvMovie entries, which the original assignment failed to do.
The ratings data in title.ratings.tsv.gz is what you’d expect:
- tconst: unique identifier of the title (which can therefore be mapped to movie metadata using a JOIN)
- averageRating: average of all the individual user ratings
- numVotes: number of votes the title has received
In order to ensure that the average ratings for modeling are indeed stable and indicative of user sentiment, I will only analyze movies that have atleast 30 user votes: as of May 10th 2025, that’s about 242k movies total. Additionally, I will not use numVotes as a model feature, since that’s a metric based more on extrinsic movie popularity rather than the movie itself.
The last major dataset is title.principals.tsv.gz, which has very helpful information on metadata such as the roles people play in the production of a movie:
- tconst: unique identifier of the title (which can be mapped to movie data using a JOIN)
- nconst: unique identifier of the principal (this is mapped to
name.basics.tsv.gzto get the principal’sprimaryName, but nothing else useful) - category: the role the principal served in the title, such as
actor,actress,writer,producer, etc. - ordering: the ordering of the principals within the title, which correlates to the order the principals appear on IMDb’s movie cast pages.
Additionally, because the datasets are so popular, it’s not the first time someone has built a IMDb ratings predictor and it’s easy to Google.

Instead of using the official IMDb datasets, these analyses are based on the smaller IMDB 5000 Movie Dataset hosted on Kaggle, which adds metadata such as movie rating, budget, and further actor metadata that make building a model much easier (albeit “number of likes on the lead actor’s Facebook page” is very extrinsic to movie quality). Using the official datasets with much less metadata is building the models on hard mode and will likely have lower predictive performance.
Although IMDb data is very popular and very well documented, that doesn’t mean it’s easy to work with.
The Initial Assignment and “Feature Engineering”
Data science take-home assignments are typically 1/2 exploratory data analysis for identifying impactful dataset features, and 1/2 building, iterating, and explaining the model. For real-world datasets, these are all very difficult problems with many difficult solutions, and the goal from the employer’s perspective is seeing more how these problems are solved rather than the actual quantitative results.
The initial Reddit post decided to engineer some expected features using pandas, such as is_sequel by checking whether a non-1 number is present at the end of a movie title and one-hot encoding each distinct genre of a movie. These are fine for an initial approach, albeit sequel titles can be idiosyncratic and it suggests that a more NLP approach to identifying sequels and other related media may be useful.
The main trick with this assignment is how to handle the principals. The common data science approach would be to use a sparse binary encoding of the actors/directors/writers, e.g. using a vector where actors present in the movie are 1 and every other actor is 0, which leads to a large number of potential approaches to encode this data performantly, such as scikit-learn’s MultiLabelBinarizer. The problem with this approach is that there are a very large number of unique actors / high cardinality — more unique actors than data points themselves — which leads to curse of dimensionality issues and workarounds such as encoding only the top N actors will lead to the feature being uninformative since even a generous N will fail to capture the majority of actors.

There are actually 624k unique actors in this dataset (Jupyter Notebook), the chart just becomes hard to read at that point.
Additionally, most statistical modeling approaches cannot account for the ordering of actors as they treat each feature as independent, and since the billing order of actors is generally correlated to their importance in the movie, that’s an omission of relevant information to the problem.
These constraints gave me an idea: why not use an LLM to encode all movie data, and build a model using the downstream embedding representation? LLMs have attention mechanisms, which will not only respect the relative ordering of actors (to give higher predictive priority to higher-billed actors, along with actor cooccurrences), but also identify patterns within movie name texts (to identify sequels and related media semantically).
I started by aggregating and denormalizing all the data locally (Jupyter Notebook). Each of the IMDb datasets are hundreds of megabytes and hundreds of thousands of rows at minimum: not quite big data, but enough to be more cognizant of tooling especially since computationally-intensive JOINs are required. Therefore, I used the Polars library in Python, which not only loads data super fast, but is also one of the fastest libraries at performing JOINs and other aggregation tasks. Polars’s syntax also allows for some cool tricks: for example, I want to spread out and aggregate the principals (4.1 million rows after prefiltering) for each movie into directors, writers, producers, actors, and all other principals into nested lists while simultaneously having them sorted by ordering as noted above. This is much easier to do in Polars than any other data processing library I’ve used, and on millions of rows, this takes less than a second:
df_principals_agg = (
df_principals.sort(["tconst", "ordering"])
.group_by("tconst")
.agg(
director_names=pl.col("primaryName").filter(pl.col("category") == "director"),
writer_names=pl.col("primaryName").filter(pl.col("category") == "writer"),
producer_names=pl.col("primaryName").filter(pl.col("category") == "producer"),
actor_names=pl.col("primaryName").filter(
pl.col("category").is_in(["actor", "actress"])
),
principal_names=pl.col("primaryName").filter(
~pl.col("category").is_in(
["director", "writer", "producer", "actor", "actress"]
)
),
principal_roles=pl.col("category").filter(
~pl.col("category").is_in(
["director", "writer", "producer", "actor", "actress"]
)
),
)
)
After some cleanup and field renaming, here’s an example JSON document for Star Wars: Episode IV - A New Hope:
{
"title": "Star Wars: Episode IV - A New Hope",
"genres": [
"Action",
"Adventure",
"Fantasy"
],
"is_adult": false,
"release_year": 1977,
"runtime_minutes": 121,
"directors": [
"George Lucas"
],
"writers": [
"George Lucas"
],
"producers": [
"Gary Kurtz",
"Rick McCallum"
],
"actors": [
"Mark Hamill",
"Harrison Ford",
"Carrie Fisher",
"Alec Guinness",
"Peter Cushing",
"Anthony Daniels",
"Kenny Baker",
"Peter Mayhew",
"David Prowse",
"Phil Brown"
],
"principals": [
{
"John Williams": "composer"
},
{
"Gilbert Taylor": "cinematographer"
},
{
"Richard Chew": "editor"
},
{
"T.M. Christopher": "editor"
},
{
"Paul Hirsch": "editor"
},
{
"Marcia Lucas": "editor"
},
{
"Dianne Crittenden": "casting_director"
},
{
"Irene Lamb": "casting_director"
},
{
"Vic Ramos": "casting_director"
},
{
"John Barry": "production_designer"
}
]
}
I was tempted to claim that I used zero feature engineering, but that wouldn’t be accurate. The selection and ordering of the JSON fields here is itself feature engineering: for example, actors and principals are intentionally last in this JSON encoding because they can have wildly varying lengths while the prior fields are more consistent, which should make downstream encodings more comparable and consistent.
Now, let’s discuss how to convert these JSON representations of movies into embeddings.
Creating And Visualizing the Movie Embeddings
LLMs that are trained to output text embeddings are not much different from LLMs like ChatGPT that just predict the next token in a loop. Models such as BERT and GPT can generate “embeddings” out-of-the-box by skipping the prediction heads of the models and instead taking an encoded value from the last hidden state of the model (e.g. for BERT, the first positional vector of the hidden state representing the [CLS] token). However, text embedding models are more optimized for distinctiveness of a given input text document using contrastive learning. These embeddings can be used for many things, from finding similar encoded inputs by identifying the similarity between embeddings, and of course, by building a statistical model on top of them.
Text embeddings that leverage LLMs are typically generated using a GPU in batches due to the increased amount of computation needed. Python libraries such as Hugging Face transformers and sentence-transformers can load these embeddings models. For this experiment, I used the very new Alibaba-NLP/gte-modernbert-base text embedding model that is finetuned from the ModernBERT model specifically for the embedding use case for two reasons: it uses the ModernBERT architecture which is optimized for fast inference, and the base ModernBERT model is trained to be more code-aware and should be able understand JSON-nested input strings more robustly — that’s also why I intentionally left in the indentation for nested JSON arrays as it’s semantically meaningful and explicitly tokenized. 3
The code (Jupyter Notebook) — with extra considerations to avoid running out of memory on either the CPU or GPU 4 — looks something like this:
device = "cuda:0"
dataloader = torch.utils.data.DataLoader(docs, batch_size=32,
shuffle=False,
pin_memory=True,
pin_memory_device=device)
dataset_embeddings = []
for batch in tqdm(dataloader, smoothing=0):
tokenized_batch = tokenizer(
batch, max_length=8192, padding=True, truncation=True, return_tensors="pt"
).to(device)
with torch.no_grad():
outputs = model(**tokenized_batch)
embeddings = outputs.last_hidden_state[:, 0].detach().cpu()
dataset_embeddings.append(embeddings)
dataset_embeddings = torch.cat(dataset_embeddings)
dataset_embeddings = F.normalize(dataset_embeddings, p=2, dim=1)

I used a Spot L4 GPU on Google Cloud Platform at a pricing of $0.28/hour, and it took 21 minutes to encode all 242k movie embeddings: about $0.10 total, which is surprisingly efficient.
Each of these embeddings is a set of 768 numbers (768D). If the embeddings are unit normalized (the F.normalize() step), then calculating the dot product between embeddings will return the cosine similarity of those movies, which can then be used to identify the most similar movies. But “similar” is open-ended, as there are many dimensions how a movie could be considered similar.
Let’s try a few movie similarity test cases where I calculate the cosine similarity between one query movie and all movies, then sort by cosine similarity to find the most similar (Jupyter Notebook). How about Peter Jackson’s Lord of the Rings: The Fellowship of the Ring? Ideally, not only would it surface the two other movies of the original trilogy, but also its prequel Hobbit trilogy.
Indeed, it worked and surfaced both trilogies! The other movies listed are about the original work, so having high similarity would be fair.
Compare these results to the “More like this” section on the IMDb page for the movie itself, which has the two sequels to the original Lord of the Rings and two other suggestions that I am not entirely sure are actually related.

What about more elaborate franchises, such as the Marvel Cinematic Universe? If you asked for movies similar to Avengers: Endgame, would other MCU films be the most similar?
| title | cossim |
|---|---|
| Avengers: Endgame (2019) | 1.0 |
| Avengers: Infinity War (2018) | 0.909 |
| The Avengers (2012) | 0.896 |
| Endgame (2009) | 0.894 |
| Captain Marvel (2019) | 0.89 |
| Avengers: Age of Ultron (2015) | 0.882 |
| Captain America: Civil War (2016) | 0.882 |
| Endgame (2001) | 0.881 |
| The Avengers (1998) | 0.877 |
| Iron Man 2 (2010) | 0.876 |
The answer is yes, which isn’t a surprise since those movies share many principals. Although, there are instances of other movies named “Endgame” and “The Avengers” which are completely unrelated to Marvel and therefore implies that the similarities may be fixated on the names.
What about movies of a smaller franchise but a specific domain, such as Disney’s Frozen that only has one sequel? Would it surface other 3D animated movies by Walt Disney Animation Studios, or something else?
| title | cossim |
|---|---|
| Frozen (2013) | 1.0 |
| Frozen II (2019) | 0.93 |
| Frozen (2010) | 0.92 |
| Frozen (2010) [a different one] | 0.917 |
| Frozen (1996) | 0.909 |
| Frozen (2005) | 0.9 |
| The Frozen (2012) | 0.898 |
| The Story of Frozen: Making a Disney Animated Classic (2014) | 0.894 |
| Frozen (2007) | 0.889 |
| Frozen in Time (2014) | 0.888 |
…okay, it’s definitely fixating on the name. Let’s try a different approach to see if we can find more meaningful patterns in these embeddings.
In order to visualize the embeddings, we can project them to a lower dimensionality with a dimensionality reduction algorithm such as PCA or UMAP: UMAP is preferred as it can simultaneously reorganize the data into more meaningful clusters. UMAP’s construction of a neighborhood graph, in theory, can allow the reduction to refine the similarities by leveraging many possible connections and hopefully avoid fixating on the movie name. However, with this amount of input data and the relatively high initial 768D vector size, the computation cost of UMAP is a concern as both factors each cause the UMAP training time to scale exponentially. Fortunately, NVIDIA’s cuML library recently updated and now you can run UMAP with very high amounts of data on a GPU at a very high number of epochs to ensure the reduction fully converges, so I did just that (Jupyter Notebook). What patterns can we find? Let’s try plotting the reduced points, colored by their user rating.

So there’s a few things going on here. Indeed, most of the points are high-rating green as evident in the source data. But the points and ratings aren’t random and there are trends. In the center giga cluster, there are soft subclusters of movies at high ratings and low ratings. Smaller discrete clusters did indeed form, but what is the deal with that extremely isolated cluster at the top? After investigation, that cluster only has movies released in 2008, which is another feature I should have considered when defining movie similarity.
As a sanity check, I faceted out the points by movie release year to better visualize where these clusters are forming:

This shows that even the clusters movies have their values spread, but I unintentionally visualized how embedding drift changes over time. 2024 is also a bizarrely-clustered year: I have no idea why those two years specifically are weird in movies.
The UMAP approach is more for fun, since it’s better for the downstream model building to use the raw 768D vector and have it learn the features from that. At the least, there’s some semantic signal preserved in these embeddings, which makes me optimistic that these embeddings alone can be used to train a viable movie rating predictor.
Predicting Average IMDb Movie Scores
So, we now have hundreds of thousands of 768D embeddings. How do we get them to predict movie ratings? What many don’t know is that all methods of traditional statistical modeling also work with embeddings — assumptions such as feature independence are invalid so the results aren’t explainable, but you can still get a valid predictive model.
First, we will shuffle and split the data set into a training set and a test set: for the test set, I chose 20,000 movies (roughly 10% of the data) which is more than enough for stable results. To decide the best model, we will be using the model that minimizes the mean squared error (MSE) of the test set, which is a standard approach to solving regression problems that predict a single numeric value.
Here are three approaches for using LLMs for solving non-next-token-prediction tasks.
Method #1: Traditional Modeling (w/ GPU Acceleration!)
You can still fit a linear regression on top of the embeddings even if feature coefficients are completely useless and it serves as a decent baseline (Jupyter Notebook). The absolute laziest “model” where we just use the mean of the training set for every prediction results in a test MSE of 1.637, but performing a simple linear regression on top of the 768D instead results in a more reasonable test MSE of 1.187. We should be able to beat that handily with a more advanced model.
Data scientists familiar with scikit-learn know there’s a rabbit hole of model options, but most of them are CPU-bound and single-threaded and would take considerable amount of time on a dataset of this size. That’s where cuML—the same library I used to create the UMAP projection—comes in, as cuML has GPU-native implementations of most popular scikit-learn models with a similar API. This notably includes support vector machines, which play especially nice with embeddings. And because we have the extra compute, we can also perform a brute force hyperparameter grid search to find the best parameters for fitting each model.
Here’s the results of MSE on the test dataset for a few of these new model types, with the hyperparameter combination for each model type that best minimizes MSE:

The winner is the Support Vector Machine, with a test MSE of 1.087! This is a good start for a simple approach that handily beats the linear regression baseline, and it also beats the model training from the Redditor’s original notebook which had a test MSE of 1.096 5. In all cases, the train set MSE was close to the test set MSE, which means the models did not overfit either.
Method #2: Neural Network on top of Embeddings
Since we’re already dealing with AI models and already have PyTorch installed to generate the embeddings, we might as well try the traditional approach of training a multilayer perceptron (MLP) neural network on top of the embeddings (Jupyter Notebook). This workflow sounds much more complicated than just fitting a traditional model above, but PyTorch makes MLP construction straightforward, and Hugging Face’s Trainer class incorporates best model training practices by default, although its compute_loss function has to be tweaked to minimize MSE specifically.
The PyTorch model, using a loop to set up the MLP blocks, looks something like this:
class RatingsModel(nn.Module):
def __init__(self, linear_dims=256, num_layers=6):
super().__init__()
dims = [768] + [linear_dims] * num_layers
self.mlp = nn.ModuleList([
nn.Sequential(
nn.Linear(dims[i], dims[i+1]),
nn.GELU(),
nn.BatchNorm1d(dims[i+1]),
nn.Dropout(0.6)
) for i in range(len(dims)-1)
])
self.output = nn.Linear(dims[-1], 1)
def forward(self, x, targets=None):
for layer in self.mlp:
x = layer(x)
return self.output(x).squeeze() # return 1D output if batched inputs
This MLP is 529k parameters total: large for a MLP, but given the 222k row input dataset, it’s not egregiously so.
The real difficulty with this MLP approach is that it’s too effective: even with less than 1 million parameters, the model will extremely overfit and converge to 0.00 train MSE quickly, while the test set MSE explodes. That’s why Dropout is set to the atypically high probability of 0.6.
Fortunately, MLPs are fast to train: training for 600 epochs (total passes through the full training dataset) took about 17 minutes on the GPU. Here’s the training results:

The lowest logged test MSE was 1.074: a slight improvement over the Support Vector Machine approach.
Method #3: Just Train a LLM From Scratch Dammit
There is a possibility that using a pretrained embedding model that was trained on the entire internet could intrinsically contain relevant signal about popular movies—such as movies winning awards which would imply a high IMDb rating—and that knowledge could leak into the test set and provide misleading results. This may not be a significant issue in practice since it’s such a small part of the gte-modernbert-base model which is too small to memorize exact information.
For the sake of comparison, let’s try training a LLM from scratch on top of the raw movie JSON representations to process this data to see if we can get better results without the possibility of leakage (Jupyter Notebook). I was specifically avoiding this approach because the compute required to train an LLM is much, much higher than a SVM or MLP model and generally leveraging a pretrained model gives better results. In this case, since we don’t need a LLM that has all the knowledge of human existence, we can train a much smaller model that only knows how to work with the movie JSON representations and can figure out relationships between actors and whether titles are sequels itself. Hugging Face transformers makes this workflow surprisingly straightforward by not only having functionality to train your own custom tokenizer (in this case, from 50k vocab to 5k vocab) that encodes the data more efficiently, but also allowing the construction a ModernBERT model with any number of layers and units. I opted for a 5M parameter LLM (SLM?), albeit with less dropout since high dropout causes learning issues for LLMs specifically.
The actual PyTorch model code is surprisingly more concise than the MLP approach:
class RatingsModel(nn.Module):
def __init__(self, model):
super().__init__()
self.transformer_model = model
self.output = nn.Linear(hidden_size, 1)
def forward(self, input_ids, attention_mask, targets=None):
x = self.transformer_model.forward(
input_ids=input_ids,
attention_mask=attention_mask,
output_hidden_states=True,
)
x = x.last_hidden_state[:, 0] # the "[CLS] vector"
return self.output(x).squeeze() # return 1D output if batched inputs
Essentially, the model trains its own “text embedding,” although in this case instead of an embedding optimized for textual similarity, the embedding is just a representation that can easily be translated into a numeric rating.
Because the computation needed for training a LLM from scratch is much higher, I only trained the model for 10 epochs, which was still twice as slow than the 600 epochs for the MLP approach. Given that, the results are surprising:

The LLM approach did much better than my previous attempts with a new lowest test MSE of 1.026, with only 4 passes through the data! And then it definitely overfit. I tried other smaller configurations for the LLM to avoid the overfitting, but none of them ever hit a test MSE that low.
Conclusion
Let’s look at the model comparison again, this time adding the results from training a MLP and training a LLM from scratch:

Coming into this post, I’m genuinely thought that training the MLP on top of embeddings would have been the winner given the base embedding model’s knowledge of everything, but maybe there’s something to just YOLOing and feeding raw JSON input data to a completely new LLM. More research and development is needed.
The differences in model performance from these varying approaches aren’t dramatic, but some iteration is indeed interesting and it was a long shot anyways given the scarce amount of metadata. The fact that building a model off of text embeddings only didn’t result in a perfect model doesn’t mean this approach was a waste of time. The embedding and modeling pipelines I have constructed in the process of trying to solve this problem have already provided significant dividends on easier problems, such as identifying the efficiency of storing embeddings in Parquet and manipulating them with Polars.
It’s impossible and pointless to pinpoint the exact reason the original Reddit poster got rejected: it could have been the neural network approach or even something out of their control such as the original company actually stopping hiring and being too disorganized to tell the candidate. To be clear, if I myself were to apply for a data science role, I wouldn’t use the techniques in this blog post (that UMAP data visualization would get me instantly rejected!) and do more traditional EDA and non-neural-network modeling to showcase my data science knowledge to the hiring manager. But for my professional work, I will definitely try starting any modeling exploration with an embeddings-based approach wherever possible: at the absolute worst, it’s a very strong baseline that will be hard to beat.
All of the Jupyter Notebooks and data visualization code for this blog post is available open-source in this GitHub repository.
-
I am not a fan of using GBT variable importance as a decision-making metric: variable importance does not tell you magnitude or direction of the feature in the real world, but it does help identify which features can be pruned for model development iteration. ↩︎
-
To get a sense on how old they are, they are only available as TSV files, which is a data format so old and prone to errors that many data libraries have dropped explicit support for it. Amazon, please release the datasets as CSV or Parquet files instead! ↩︎
-
Two other useful features of
gte-modernbert-basebut not strictly relevant to these movie embeddings are a) its a cased model so it can identify meaning from upper-case text and b) it does not require a prefix such assearch_queryandsearch_documentas nomic-embed-text-v1.5 does to guide its results, which is an annoying requirement for those models. ↩︎ -
The trick here is the
detach()function for the computed embeddings, otherwise the GPU doesn’t free up the memory once moved back to the CPU. I may or may not have discovered that the hard way. ↩︎ -
As noted earlier, minimizing MSE isn’t a competition, but the comparison on roughly the same dataset is good for a sanity check. ↩︎




An internal Microsoft memo has leaked. It was written by Julia Liuson, president of the Developer Division at Microsoft and GitHub. The memo tells managers to evaluate employees based on how much they use internal AI tools like the various Copilots: [Business Insider]
AI is now a fundamental part of how we work. Just like collaboration, data-driven thinking, and effective communication, using AI is no longer optional — it’s core to every role and every level.
Liuson told managers that AI “should be part of your holistic reflections on an individual’s performance and impact.”
Let’s be clear: this is a confession of abject failure.
Microsoft’s AI tools don’t work. Microsoft AI doesn’t make you more effective. Microsoft AI won’t do the job better.
If it did, Microsoft staff would be using it already. The competition inside Microsoft is vicious. If AI would get them ahead of the other guy, they’d use it.
We already know that when AI saves someone time at work, it’s because they can fob work off onto someone else. Total work doesn’t go down, and total productivity doesn’t go up.
But Microsoft is desperate to sell AI to anyone it can, because the CEO, Satya Nadella, has a bee in his bonnet. Nadella has decreed: everyone will use AI.
Even though it doesn’t work.
We should expect some enterprising Microsoft coder to come up with an automated AI agent system that racks up chatbot metrics for them — while they get on with their actual job.
Most people know that AI has made unbelievable progress over the last fifteen years– especially in the last five. It might feel like that progress is *inevitable* – although large paradigm-shift-level breakthroughs are uncommon, we march on anyway through a stream of slow & steady progress. In fact, some researchers have recently declared a “Moore’s Law for AI” where the computer’s ability to do certain things (in this case, certain types of coding tasks) increases exponentially with time:

Although I don’t really agree with this specific framing for a number of reasons, I can’t deny the trend of progress. Every year, our AIs get a little bit smarter, a little bit faster, and a little bit cheaper, with no end in sight.
Most people think that this continuous improvement comes from a steady supply of ideas from the research community across academia – mostly MIT, Stanford, CMU – and industry – mostly Meta, Google, and a handful of Chinese labs, with lots of research done at other places that we’ll never get to learn about.
And we certainly have made a lot of progress due to research, especially on the systems side of things. This is how we’ve made models cheaper in particular. Let me cherry-pick a few notable examples from the last couple years:
- in 2022 Stanford researchers gave us FlashAttention, a better way to utilize memory in language models that’s used literally everywhere;
- in 2023 Google researchers developed speculative decoding, which all model providers use to speed up inference (also developed at DeepMind, I believe concurrently?)
- in 2024 a ragtag group of internet fanatics developed Muon, which seems to be a better optimizer than SGD or Adam and may end up as the way we train language models in the future
- in 2025 DeepSeek released DeepSeek-R1, an open-source model that has equivalent reasoning power to similar closed-source models from AI labs (specifically Google and OpenAI)
So we’re definitely figuring stuff out. And the reality is actually cooler than that: we’re engaged in a decentralized globalized exercise of Science, where findings are shared openly on ArXiv and at conferences and on social media and every month we’re getting incrementally smarter.
If we’re doing so much important research, why do some argue that progress is slowing down? People are still complaining. The two most recent huge models, Grok 3 and GPT-4.5, only obtained a marginal improvement on capabilities of their predecessors. In one particularly salient example, when language models were evaluated on the latest math olympiad exam, they scored only 5%, indicating that recent announcements may have been overblown when reporting system ability.
And if we try to chronicle the *big* breakthroughs, the real paradigm shifts, they seem to be happening at a different rate. Let me go through a few that come to mind:
LLMs in four breakthroughs
1. Deep neural networks: Deep neural networks first took off after the AlexNet model won an image recognition competition in 2012
2. Transformers + LLMs: in 2017 Google proposed transformers in Attention Is All You Need, which led to BERT (Google, 2018) and the original GPT (OpenAI, 2018)
3. RLHF: first proposed (to my knowledge) in the InstructGPT paper from OpenAI in 2022
4. Reasoning: in 2024 OpenAI released O1, which led to DeepSeek R1
If you squint just a little, these four things (DNNs → Transformer LMs → RLHF → Reasoning) summarize everything that’s happened in AI. We had DNNs (mostly image recognition systems), then we had text classifiers, then we had chatbots, now we have reasoning models (whatever those are).
Say we want to make a fifth such breakthrough; it could help to study the four cases we have here. What new research ideas led to these groundbreaking events?
It’s not crazy to argue that all the underlying mechanisms of these breakthroughs existed in the 1990s, if not before. We’re applying relatively simple neural network architectures and doing either supervised learning (1 and 2) or reinforcement learning (3 and 4).
Supervised learning via cross-entropy, the main way we pre-train language models, emerged from Claude Shannon’s work in the 1940s.
Reinforcement learning, the main way we post-train language models via RLHF and reasoning training, is slightly newer. It can be traced to the introduction of policy-gradient methods in 1992 (and these ideas were certainly around for the first edition of the Sutton & Barto “Reinforcement Learning” textbook in 1998).
If our ideas aren’t new, then what is?
Ok, let’s agree for now that these “major breakthroughs” were arguably fresh applications of things that we’d known for a while. First of all – this tells us something about the *next* major breakthrough (that “secret fifth thing” I mentioned above). Our breakthrough is probably not going to come from a completely new idea, rather it’ll be the resurfacing of something we’ve known for a while.
But there’s a missing piece here: each of these four breakthroughs enabled us to learn from a new data source:
1. AlexNet and its follow-ups unlocked ImageNet, a large database of class-labeled images that drove fifteen years of progress in computer vision
2. Transformers unlocked training on “The Internet” and a race to download, categorize, and parse all the text on The Web (which it seems we’ve mostly done by now)
3. RLHF allowed us to learn from human labels indicating what “good text” is (mostly a vibes thing)
4. Reasoning seems to let us learn from “verifiers”, things like calculators and compilers that can evaluate the outputs of language models
Remind yourself that each of these milestones marks the first time the respective data source (ImageNet, The Web, Humans, Verifiers) was used at scale. Each milestone was followed by a frenzy of activity: researchers compete to (a) siphon up the remaining useful data from any and all available sources and (b) make better use of the data we have through new tricks to make our systems more efficient and less data-hungry. (I expect we’ll see this trend in reasoning models throughout 2025 and 2026 as researchers compete to find, categorize, and verify everything that might be verified.)

How much do new ideas matter?
There’s something to be said for the fact that our actual technical innovations may not make a huge difference in these cases. Examine the counterfactual. If we hadn’t invented AlexNet, maybe another architecture would have come along that could handle ImageNet. If we never discovered Transformers, perhaps we would’ve settled with LSTMs or SSMs or found something else entirely to learn from the mass of useful training data we have available on the Web.
This jibes with the theory some people have that nothing matters but data. Some researchers have observed that for all the training techniques, modeling tricks, and hyperparameter tweaks we make, the thing that makes the biggest difference by-and-large is changing the data.
As one salient example, some researchers worked on developing a new BERT-like model using an architecture other than transformers. They spent a year or so tweaking the architecture in hundreds of different ways, and managed to produce a different type of model (this is a state-space model or “SSM”) that performed about equivalently to the original transformer when trained on the same data.
This discovered equivalence is really profound because it hints that *there is an upper bound to what we might learn from a given dataset*. All the training tricks and model upgrades in the world won’t get around the cold hard fact that there is only so much you can learn from a given dataset.
And maybe this apathy to new ideas is what we were supposed to take away from The Bitter Lesson. If data is the only thing that matters, why are 95% of people working on new methods?
Where will our next paradigm shift come from? *(YouTube…maybe?)
The obvious takeaway is that our next paradigm shift isn’t going to come from an improvement to RL or a fancy new type of neural net. It’s going to come when we unlock a source of data that we haven’t accessed before, or haven’t properly harnessed yet.
One obvious source of information that a lot of people are working towards harnessing is video. According to a random site on the Web, about 500 hours of video footage are uploaded to YouTube *per minute*. This is a ridiculous amount of data, much more than is available as text on the entire internet. It’s potentially a much richer source of information too as videos contain not just words but the inflection behind them as well as rich information about physics and culture that just can’t be gleaned from text.
It’s safe to say that as soon as our models get efficient enough, or our computers grow beefy enough, Google is going to start training models on YouTube. They own the thing, after all; it would be silly not to use the data to their advantage.
A final contender for the next “big paradigm” in AI is a data-gathering systems that some way embodied– or, in the words of a regular person, robots. We’re currently not able to gather and process information from cameras and sensors in a way that’s amenable to training large models on GPUs. If we could build smarter sensors or scale our computers up until they can handle the massive influx of data from a robot with ease, we might be able to use this data in a beneficial way.
It’s hard to say whether YouTube or robots or something else will be the Next Big Thing for AI. We seem pretty deeply entrenched in the camp of language models right now, but we also seem to be running out of language data pretty quickly. But if we want to make progress in AI, maybe we should stop looking for new ideas, and start looking for new data.
Many authors will tell you how to write mathematics clearly and correctly.
But few will tell you how to write it with style and panache, so as to attract the oohs, aahs, and swiveling heads of passers-by.
In that spirit, allow me to channel the men’s fashion guy on Twitter. (Note to the men’s fashion guy on Twitter: please never look at me or my clothes.) Here are a few side-by-side case studies in how to make your mathematics look good:

Sure, some polynomials look fabulous when factored. Also, some athletic 23-year-olds look good in midriff-baring tops. This doesn’t mean we should all try it.
Better to leave something to the imagination; it’s a sign of maturity.

They’re called radicals for a reason, folks. Don’t conform to algebraic conventions. Give the people something to talk about.

I’m not against f-1 notation in general. That would be like opposing casual wear at the office; no point shaking one’s fist at a ship that long ago sailed. (And anyway, why should x-1 be reserved for reciprocals? Isn’t that just a clever and illuminating convention? Any use of negative exponents is already a high-fashion abstraction.)
Anyway, in this particular case, it’s madness to use the dainty superscript when there’s a robust and appealing alternative.

Okay, yes, if you’re actually calculating anything from the limit definition of a derivative, you should go with the more familiar h going to 0 definition.
But be honest. Are you working with the definition of a derivative? Is this the 19th century? Are you a yeoman farmer and/or a Cauchy-era analyst?
No?
Well, then, you’re not bringing this definition to work. You’re using it to make a point: namely, that the derivative is what happens to a slope as the two points draw closer together. And that point is best made with this stylish latter version.

I hesitate to wade into the long-simmering /phi vs. /varphi debates.
But c’mon, folks.
If we can’t agree on such an obvious matter of aesthetics, then I fear we may be approaching the end of our existence as a coherent civilization. Perhaps, in a few decades, the /phi advocates can be resettled on the surface of the moon, where they can build their own sorry little society, beyond the intimidating shadow of our superior fashion sense.

Ah, variance, you minxy concept.
I almost went the other way on this one. After all, is this not the opposite of my advice on the definition of a derivative? Here, am I not promoting easy manipulation over conceptual illumination?
Indeed I am. And that’s because we’re perpetually manipulating variance. The only thing you want to do with that first definition is change speedily into the second one.

I know I’ll ruffle some feathers with this one. Good. Those feathers look silly. They need ruffling.
Now, have I disrupted the beauty of an equation that “unites the five fundamental constants of mathematics”?
Or, have I just revealed that “-1 + 1 = 0” is not as profound a sentiment as some folks think?
With the rise of the internet came the need to find information more quickly. The concept of search engines came into this space to fill this need, with a relatively basic initial design.
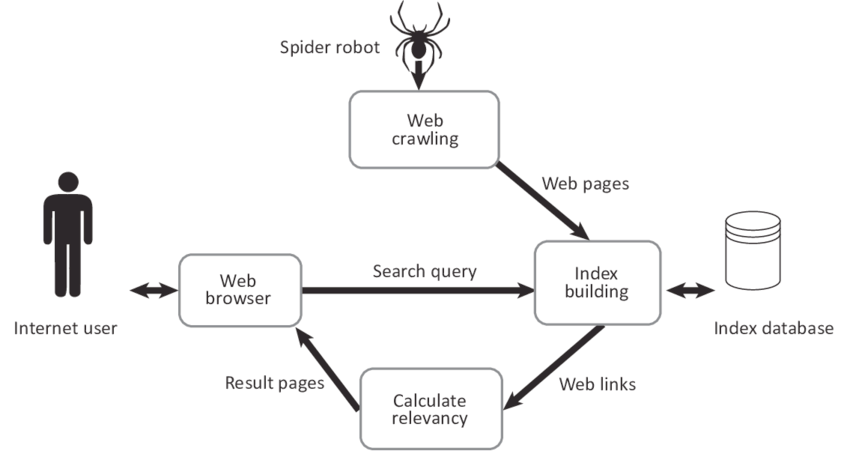
This is the basis of the giant megacorp Google, whose claim to fame was they made the best one of these. Into this stack they inject ads, both ads inside the sites themselves and then turning the search results themselves into ads.
As time went on, what we understood to be "Google search" was actually a pretty sophisticated machine that effectively determined what websites lived or died. It was the only portal that niche websites had to get traffic. Google had the only userbase large enough for a website dedicated to retro gaming or VR headsets or whatever to get enough clicks to pay their bills.
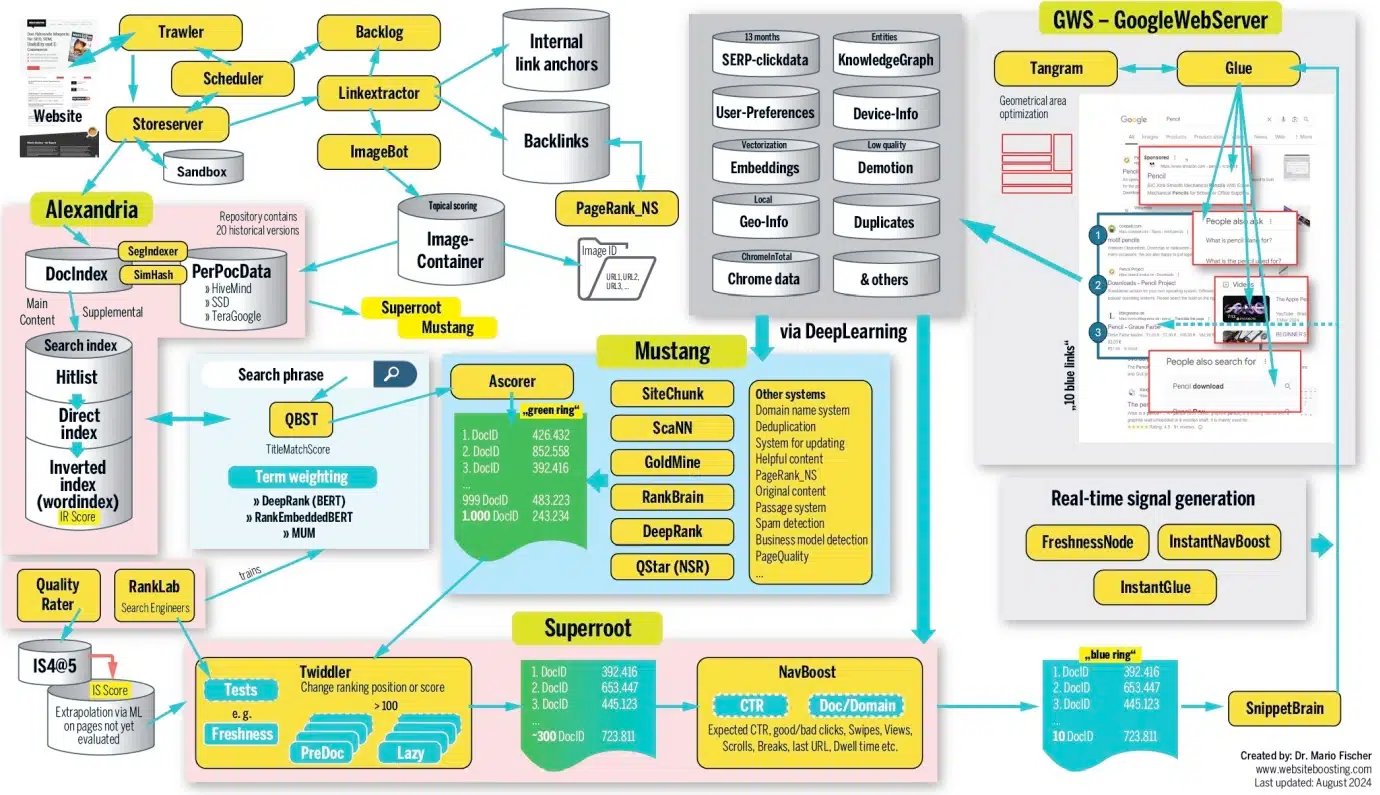
Despite the complexity, the basic premise remained. Google steers traffic towards your site, the user gets the answer from your site and then everyone is happy. Google showed some ads, you showed some ads, everyone showed everyone on Earth ads.
This incredibly lucrative setup was not enough, however, to drive endless continous growth, which is now the new expectation of all tech companies. It is not enough to be fabulously profitable, you must become Weyland-Yutani. So now Google is going to break this long-standing agreement with the internet and move everything we understand to be "internet search" inside their silo.

Zero-Click Results
In March 2024 Google moved to embed LLM answers in their search results (source). The AI Overview takes the first 100 results from your search query, combines their answers and then returns what it thinks is the best answer. As expected, websites across the internet saw a drop in traffic from Google. You started to see a flood of smaller websites launch panic membership programs, sell off their sites, etc.
It became clear that Google has decided to abandon the previous concept of how internet search worked, likely in the face of what it considers to be an existential threat from OpenAI. Maybe the plan was always to bring the entire search process in-house, maybe not, but OpenAI and its rise to fame seems to have forced Google's hand in this space.
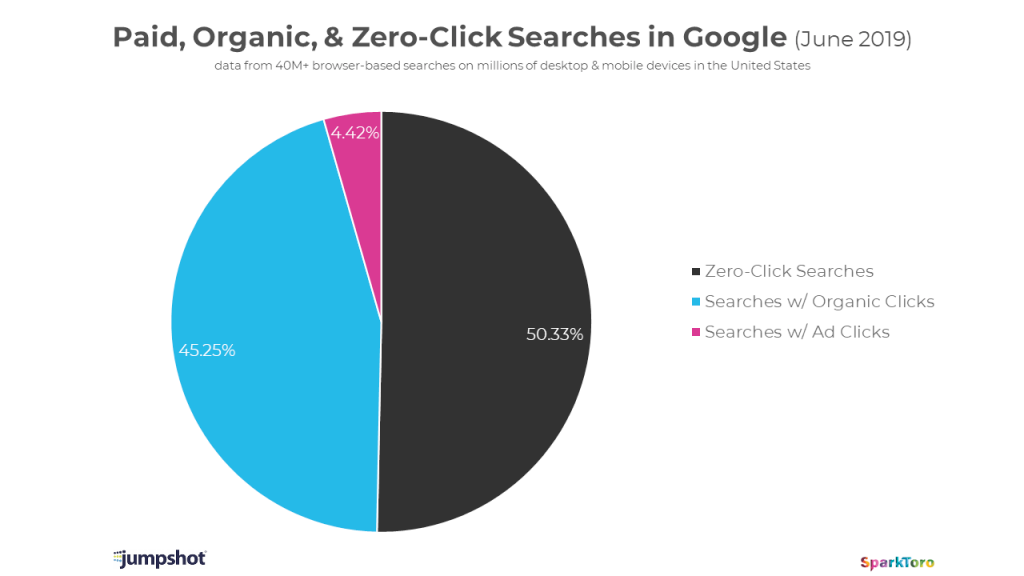
This is not a new thing, Google has been moving in this direction for years. It was a trend people noticed going back to 2019.
It appears the future of Google Search is going to be a closed loop that looks like the following:
- Google LLM takes the information from the results it has already ingested to respond to most questions.
- Companies will at some point pay for their product or service to be "the answer" in different categories. Maybe this gets disclosed, maybe not, maybe there's just a little i in the corner that says "these answers may be influenced by marketing partners" or something.
- Google will attempt to reassure strategic partners that they aren't going to kill them, while at the same time turning to their relationship with Reddit to supply their "new data".
This is all backed up by data from outside the Google ecosystem confirming that the ratio of scrapes to click is going up. Basically it's costing more for these services to make their content available to LLMs and they're getting less traffic from them.
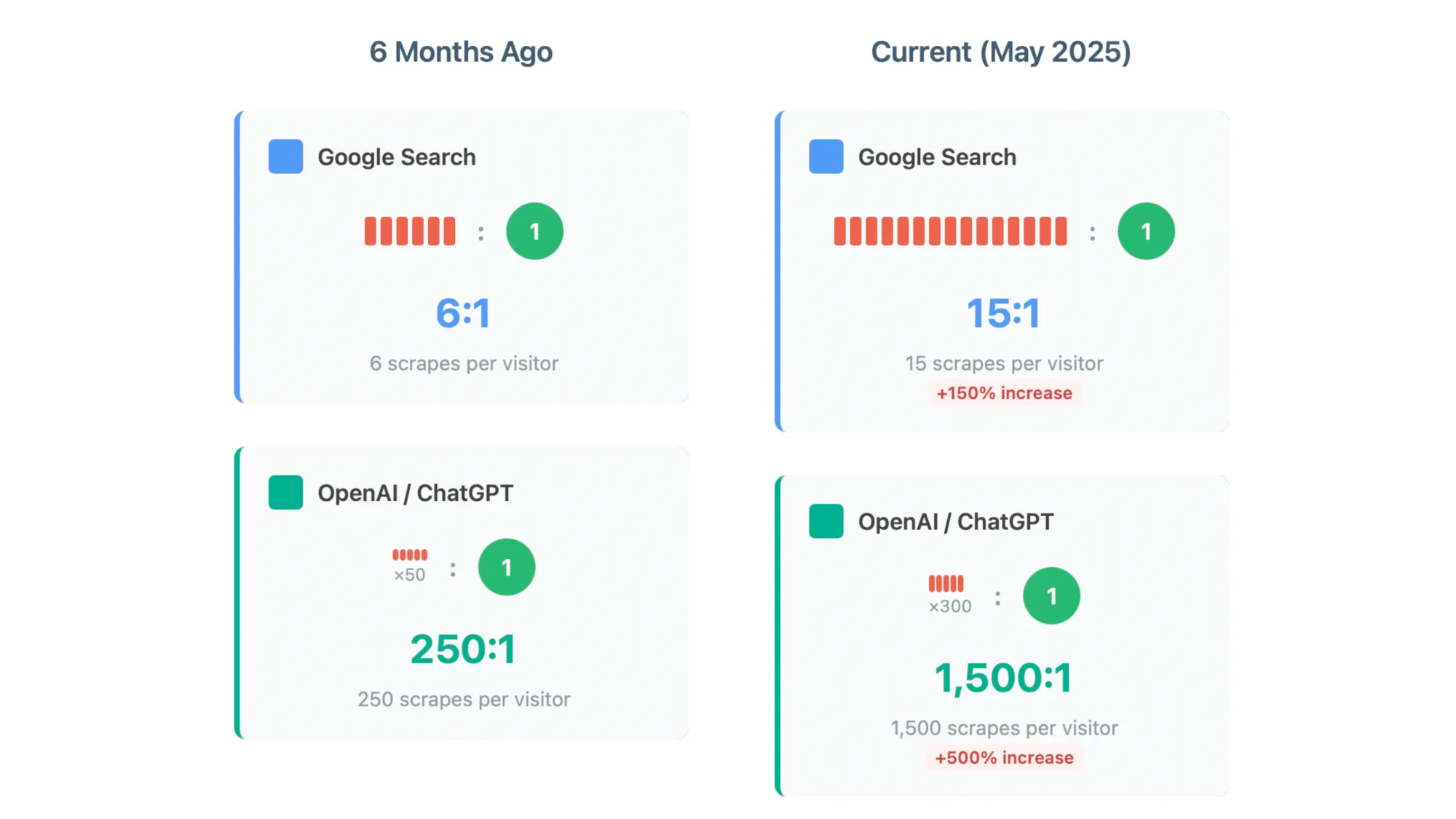
This new global strategy makes sense, especially in the context of the frequent Google layoffs. Previously it made strategic sense to hold onto all the talent they could, now it doesn't matter because the gates are closing. Even if you had all the ex-Google engineers money could buy, you can't make a better search engine because the concept is obsolete. Google has taken everything they need from the internet, it no longer requires the cooperation or goodwill of the people who produce that content.
What happens next?
So the source of traffic for the internet is going to go away. My guess is there will be some effort to prevent this, some sort of alternative Google search either embraced or pushed by people. This is going to fail, because Google is an unregulated monopoly. Effectively because the US government is so bad at regulating companies and so corrupt with legalized bribery in the form of lobbying, you couldn't stop Google at this point even if you wanted to.
- Android is the dominant mobile platform on Earth
- Chrome is the dominant web browser
- Apple gets paid to make the other mobile platform default to Google
- Firefox gets paid to make the other web browser default to Google
While the US Department of Justice has finally decided to doing something, it's almost too late to make a difference. https://www.justice.gov/opa/pr/department-justice-prevails-landmark-antitrust-case-against-google
Even if you wanted to and had a lot of money to throw at the problem, it's too late. If Apple made their own search engine and pointed iOS to it as the default and paid Firefox to make it the default, it still wouldn't matter. The AI Overview is a good enough answer for most questions and so convincing consumers to:
- switch platforms
- and go back to a two/three/four step process compared to a one step process is a waste of time.
I'm confident there will still be sites doing web searching, but I suspect given the explosion in AI generated slop it's going to be impossible to use them even if you wanted to. We're quickly reaching a point where it would be possible to generate a web page on demand, meaning the capacity of the slop-generation exceeds the capacity of humans to fight it.
Because we didn't regulate the internet, we're going to end up with an unbreakable monopoly on all human knowledge held by Microsoft and Google. Then because we didn't learn anything we're going to end up with a system that can produce false data on demand and make it impossible to fact check anything that the LLM companies return. Paid services like Kogi will be the only search engines worth trying.
Impact down the line
So I think you are going to see a rush of shutdowns and paywalls like you've never seen before. In some respects, it is going to be a return to the pre-Google internet, where it will once again be important that consumers know your domain name and go directly to your site. It's going to be a massive consolidation of the internet down and I think the ad-based economy of the modern web will collapse. Google was the ad broker, but now they're going to operate like Meta and keep the entire cycle inside their system.
My prediction is that this is going to basically destroy any small or medium sized business that attempts to survive with the model of "produce content, get paid per visitor through ads". Everything instead is going to get moved behind aggressive paywalls, blocking archive.org. You'll also see prices go way up for memberships. Access to raw, human produced information is going to be a premium product, not something for everyday people. Fake information will be free.
Anyone attempting to make an online store is gonna get mob-style shakedown. You can either pay Amazon to let consumers see your product or you can pay Google to have their LLM recommend your product or you can (eventually) pay OpenAI/Microsoft to do it. I also think these companies will use this opportunity to dramatically reprice their advertising offerings. I don't think it'll be cheap to get the AI Summary to recommend your frying pan.
I suspect there will be a brief spike in other forms of marketing spend, like podcasts, billboards, etc. When companies see the sticker shock from Google they're going to explore other avenues like social media spend, influencers, etc. But all those channels are going to be eaten by the LLM snake at the same time.
If consumers are willing to engage with an LLM-generated influencer, that'll be the direction companies go in because they'll be cheaper and more reliable. Podcast search results are gonna be flooded with LLM-generated shows and my guess is that they're going to take more of the market share than anyone wants to admit. Twitch streaming has already moved from seeing the person to seeing an anime-style virtual overlay where you don't see the persons face. There won't be a reason for an actual human to be involved in that process.
End Game
My prediction is that a lot of the places that employ technical people are going to disappear. FAANG isn't going to be hiring at anywhere near the same rate they were before, because they won't need to. I don't need 10,000 people maintaining relationships with ad sellers and ad buyers or any of the staff involved in the maintenance or improvement of those systems.
The internet is going to return to more of its original roots, which are niche fan websites you largely find through social media or word of mouth. These sites aren't going to be ad driven, they'll be membership driven. Very few of them are going to survive. Subscription fatigue is a real thing and the math of "it costs a lot of money to pay people to write high quality content" isn't going to go away.
In a relatively short period of time, it will go from "very difficult" to absolutely impossible to launch a new commercially viable website and have users organically discover that website. You'll have to block LLM scrapers and need a tremendous amount of money to get a new site bootstrapped. Welcome to the future, where asking a question costs $4.99 and you'll never be able to find out if the answer is right or not.