This isn’t just my favorite piece about gaming this year; it’s my favorite piece about gaming in memory. (No, you don’t need to be familiar with the Pokémon series. Anything this Gen-Xer knows about it comes from rap lyrics.) Joseph Earl Thomas happens to be a competitive Pokémon player and an astute cultural critic, which makes his remit far wider than a mere subculture story: In interrogating why Pokémon’s competitive scene has always looked blessedly different from other games’, he brings all of himself to the project, in the best way possible.
It’s also nice that New Orleans is, much like Outkast’s Aquemini, another Black experience. I bumped into this dude at Louis Armstrong Park who looked like Wayne in his Carter III era; we were both quacking back at the ducks, and he offered me weed as we watched them play (“Nah, I’m good,” I said reflexively.) We compared the qualities of cuteness between turtles and geese—which, in miniature, we agreed, are their own kind of Pokémon. Then we talked about Jordans for twenty-four minutes, as we both had on crisp thirteens in opposing color schemes. On the street, this woman with a friend who looks like my daughter’s mom stared me dead in the face as we passed each other, took off her headphones playing what sounded like GloRilla, looked me up and down and said, “Mm-hmmm,” and my new friend with the wrong color thirteens on watched her walk away and said the same thing. That’s how it felt to be in New Orleans, mixed-up, of course, with memories of Kanye’s post-Katrina George Bush beef, and Sarah Broom’s hundred-year inscription against dilapidation in The Yellow House, and even my last visit, during the New Orleans Poetry Festival, where I predictably fell in love with a poet and roamed the streets bedecked in Mardi Gras beads behind (or in front of?) a handful of friends from VONA and had forgotten that other forms of joy even existed. All of which is to say that sure, I’m working this Pokémon tournament, but it’s also easy to recall the comment that Arthur Jafa once made about how twerking is its own form of Black virtuosity, be it at Magic City or elsewhere; we all make sacrifices for our art, for the greater good and all that.
Project CETI is a large-scale effort to decode whale speech. If AI models do learn a universal language, we might be able to use it to talk to whales.
Growing up, I sometimes played a game with my friends called “Mussolini or Bread.”
It’s a guessing game, kind of like Twenty Questions. The funny name comes from the idea that, in the space of everything, ‘Mussolini’ and ‘bread’ are about as far away from each other as you can get.
Thanks for reading Token for Token! Subscribe for free to receive new posts and support my work.
One round might go like this:
Is it closer to Mussolini or bread? Mussolini.
Is it closer to Mussolini or David Beckham? Uhh, I guess Mussolini. (Ok, they’re definitely thinking of a person.)
Is it closer to Mussolini or Bill Clinton? Bill Clinton.
Is it closer to Bill Clinton or Pelé? Bill Clinton, I think.
Is it closer to Bill Clinton or Grace Hopper? Grace Hopper.
Is it closer to Grace Hopper or Richard Hamming? Richard Hamming.
Is it closer to Richard Hamming or Claude Shannon? You got it, I was thinking of Claude Shannon.
Hopefully you get the point. By successively narrowing down the space of possible things or people, we’re able to guess almost anything.
How is this game possible? Mussolini or Bread only works because you and I have a shared sense of semantics. Before we played this game, we never talked about whether Claude Shannon is semantically ‘closer’ to Mussolini or Beckham. We never even talked about what it means for two things to be ‘close’, even, or agreed on rules to the game.
As you might imagine, the edge cases in M or B can be controversial. But I’ve played this game with many people and people tend to “just get it” on their first try. How is that possible?
A universal sense of semantics
One explanation for why this game works is that there is only one way in which things are related, and this comes from the underlying world we live in. Put another way, our brains build up complicated models of the world in which we live, and the model of the world that my brain relies on is very similar to the one in yours. In fact, our brains’ models of the world are so similar that we can narrow down almost any concept by successively refining the questions we ask, a-la Mussolini or Bread.
Let’s try to explain this through the lens of compression. One perspective on AI is that we’re just learning to compress all the data in the world. In fact, the task of language modeling (predicting the next word) can be seen as a compression task, ever since Shannon’s source coding theorem formalized the relationship between probability distributions and compression algorithms.
Intelligence is compression, and compression follows scaling laws. I like reminding people that the original work on scaling laws came from Baidu in 2017.
And with better probability distributions comes better compression. In practice, we find that a model that can compress real data better knows more about the world. And thus there is a duality between compression and intelligence. Compression is intelligence. Some have even said compression may be the way to AGI. Ilya gave a famously incomprehensible talk about the connections between intelligence and compression.
Last year some folks at DeepMind wrote a paper simply titled Language Modeling Is Compression and actually tested different language models’ ability to compress various data modalities. Across the board, they found that smarter language models are better compressors. (Of course, this is what we’d expect, given the source coding theorem.)
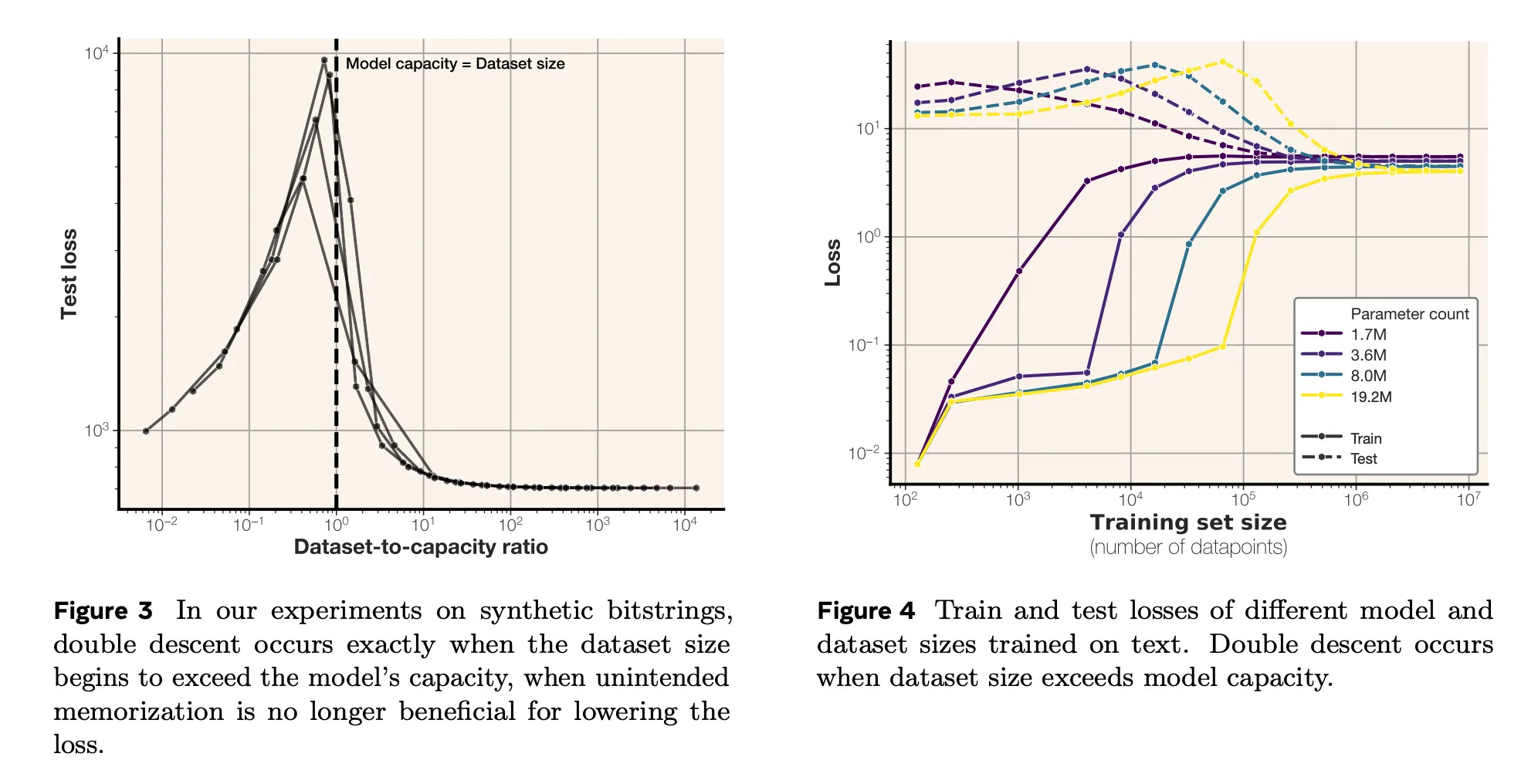
And learning to compress is exactly how models end up generalizing. Some of our recent work has analyzed models’ compression behavior in the limit of training: we train models for infinitely long on datasets of varying size.
Figures from our recent work, How much can language models memorize? Generalization only begins when compression is no longer possible, since the model can’t store data points separately and is forced to combine things.
When a model can fit the training dataset perfectly (left side of both graphs) we see that it memorizes data really well, and totally fails to generalize. But when the dataset gets too big, and the model can no longer fit all of the data in its parameters, it’s forced to “combine” information from multiple datapoints in order to get the best training loss. This is where generalization occurs.
And the central idea I’ll push here is that when generalization occurs, it usually occurs in the same way, even within different models. From the compression perspective, under a given architecture and within a fixed number of parameters, there is only one way to compress the data well. This sounds like a crazy idea–and it is– but across different domains and models, there turns out to be a lot of evidence for this phenomenon.
Remember what these models are really doing is modeling the relationships between things in the world. In some sense there’s only one correct way to model things, and that’s the true model, the one that perfectly reflects the reality in which we live. Perhaps an infinitely large model with infinite training data would be a perfect simulator of the world itself.
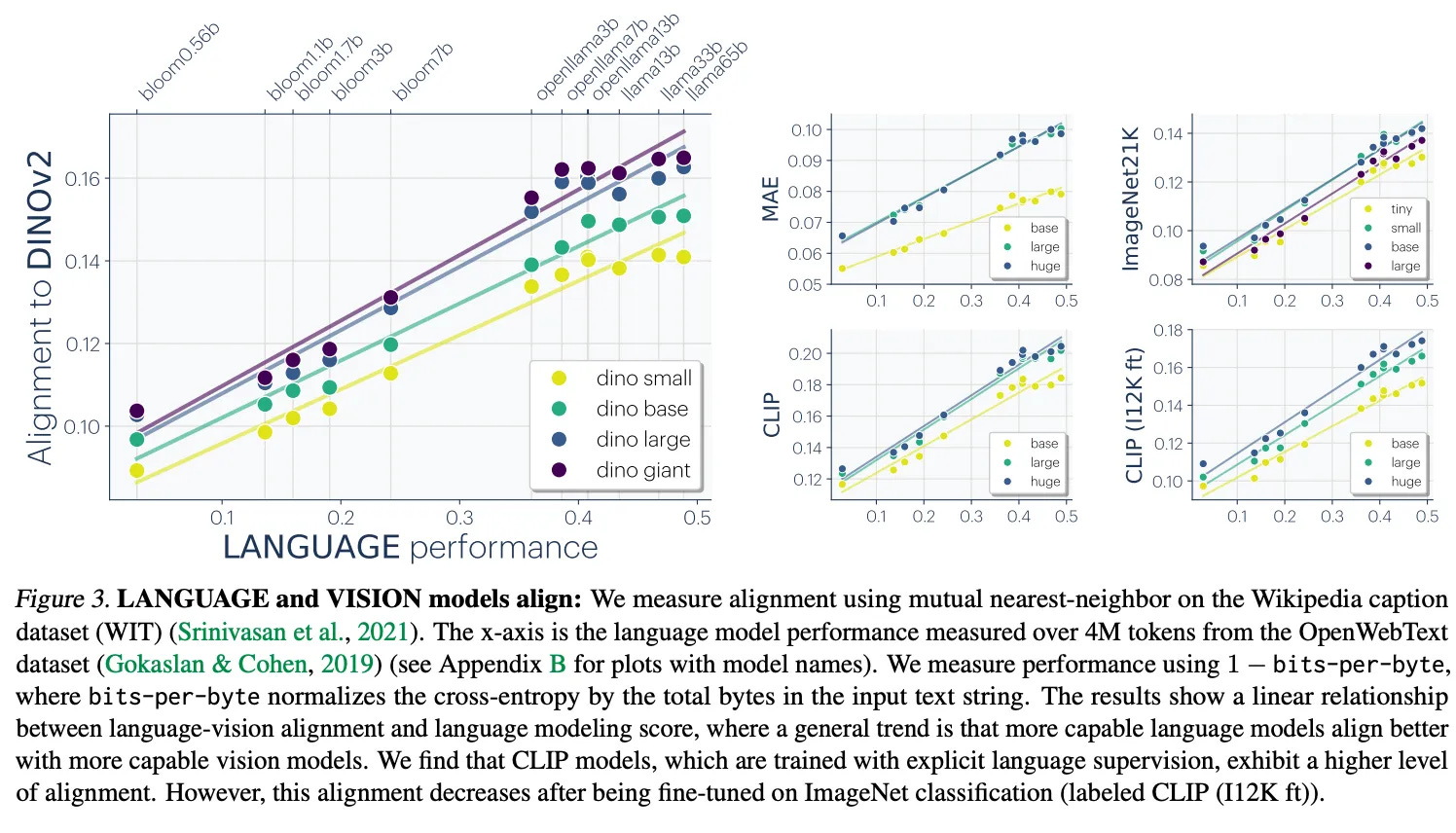
As models have gotten bigger, their similarities have become more apparent. The theory that models are converging to a shared underlying representation space was formalized in The Platonic Representation Hypothesis,a position paper written by a group of MIT researchers in 2024.
The Platonic Representation Hypothesis argues that as models get bigger, they’re learning more and more of the same features. They provide evidence for this in vision and language.
The Platonic Representation Hypothesis argues that models are converging to a shared representation space, and this is becoming more true as we make models bigger and smarter. This is true in text and language, at a minimum,
Remember the trends in scaling show that models are getting all three of bigger, smarter, and more efficient every year. That means that we can expect models to get more similar, too, as the years go on.
A brief aside on embedding inversion
The evidence for the Platonic Representation Hypothesis is compelling. But is it useful? Before I explain how to take advantage of the PRH, I have to give a bit of background on a problem of embedding inversion.
I worked for a year or so of my PhD on this problem: given a representation vector from a neural network, can we infer what text was inputted to the network?
We thought inversion should be possible because results on ImageNet showed that they could do very effective reconstruction given only a model’s output of 1000 class probabilities. This is extremely unintuitive. Apparently knowing that an image is 0.0001% parakeet and 0.0017% baboon is useful enough to infer not only the true class but lots of irrelevant information like facial structure, pose, and background details.
In the realm of text, the problem looks easy on its face, because typical embedding vectors have ~1000 floating-point numbers in them, or around 16 KB of data. If you store 16KB of text, it can represent quite a lot. Since we were working with datapoints on the level of long sentences or short documents, it seemed reasonable that we would be able to do inversion quite well.
But it turns out to be really hard. This mostly comes about because embeddings are in some sense extremely compressed: since similar texts have similar embeddings, it becomes very difficult to distinguish between two embeddings that similar-but-different data. So our models could output something close to the embedding, but almost never the exactly-correct text.
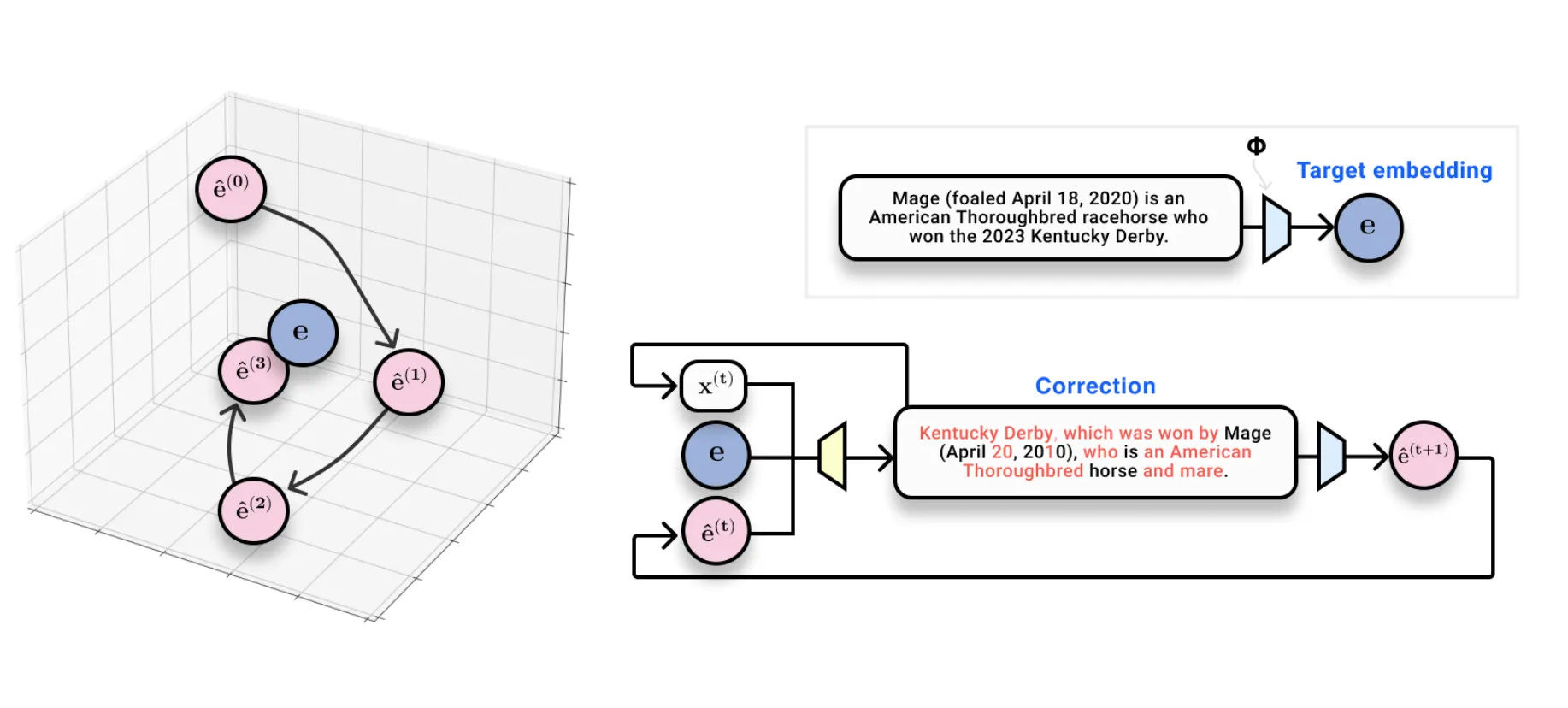
We ended up getting around this problem by using a primitive form of test-time compute: we made many queries to the embedding space and built a model that could “narrow down” the true text by iteratively improving itself in embedding space. Our system looks kind of like a learned optimizer that takes text-based steps to move position in embedding space.
Iterative refinement is an extremely effective method for embedding inversion (read more here).
This new approach turns out to work very well. Given an embedding model, we were able to invert text at the level of a long sentence with 94% exact accuracy.
Harnessing Plato for embedding inversion
We were very pleased with ourselves after making that method work. This had a whole lot of implications for the new model of the vector database: sharing vectors, apparently, is equivalent to sharing the text those vectors represent.
But unfortunately our method was embedding-specific. It wasn’t clear that it could transfer to future embedding models or private fine-tunes that we didn’t have access to. And it required making a lot of queries to the embedding model we knew: training the models took millions of embeddings.
We thought that this shouldn’t be the case. If the Platonic Representation Hypothesis is true, and different models (in some sense) are learning the same thing, we should be able to build one universal embedding inverter and use it for any kind of model. This idea set us off on a multi-year quest to “harness” the PRH and build a universal embedding inverter.
We started by expressing our problem as a mathematical one. Given a bunch of embeddings from model A, and a bunch of embeddings from model B, can we learn to map from A→B (or B→A)?
Importantly, we don’t have any correspondence, i.e. pairs of texts with representations in both A and B. That’s why this problem is hard. We want to learn to align the spaces of A and B in some way so that we can ‘magically’ learn how to convert between their spaces.
We realized after a while that this problem has been solved at least once in the deep learning world: work on a model called CycleGAN proposed a way to translate between spaces without correspondence using a method called cycle consistency:
Just imagine that the horses and zebras above are a piece of text from model A being translated into the space of model B and back. If this works for zebras and horses, why shouldn’t it work for text?
And, after at least a year of ruthlessly debugging our own embedding-specific version of CycleGAN, we started to see signs of life. In our unsupervised matching task we started to produce GIFs like this:
After training a CycleGAN-like model for mapping between embedding spaces, vec2vec learns to ‘magically’ align them. Hooray for the Platonic Representation Hypothesis!
To us, this was an incredible step forward, and proof for an even stronger claim we call the “Strong Platonic Representation Hypothesis”. Models’ representations share so much structure that we can translate between them, even without having knowledge of individual points in either of the spaces. This meant that we could do unsupervised conversion between models, as well as invert embeddings mined from databases where we know nothing about the underlying model.
Universality in Circuits
Some additional evidence for the PRH comes from the world of mechanistic interpretability, where researchers attempt to reverse-engineer the inner workings of models. Work on Circuits in 2020 found very similar functionalities in very different models:
Universal feature dectors from Circuits (2020). Different networks exhibit remarkably similar behaviors.
More recently, there’s been some action around a method for feature discretization known as sparse autoencoders (SAEs). SAEs take a bunch of embeddings and learn a dictionary of interpretable features that can reproduce those embeddings with minimal loss.
Many are observing that if you train SAEs on two different models, they often learn many of the same features. There’s even been some recent work on ‘unsupervised concept discovery’, a suite of methods that can compare two SAEs to find feature overlap:
Universal features from Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment (2025).
Since the PRH conjectures that models become more aligned as they get stronger, I suspect this type of common circuit discovery will only grow more common.
What can we make of all this?
Besides being a deep philosophical idea, the Platonic Representation Hypothesis turns out to be an important practical insight with real-world implications. As the mechanistic interpretability community develops better tools for reverse-engineering models, I expect them to find more and more similarities; as models get bigger, this will become more common.
Linear A is an ancient Greek text that humans have never been able to decrypt. Perhaps the Platonic Representation Hypothesis gives us hope for one day decoding it back to English.
As for our method (vec2vec), we found strong evidence, but things are still brittle. It seems clear that we can learn an unsupervised mapping between text-based models that are trained on the Internet, as well as CLIP-like image-text embeddings.
It’s not obvious whether we can map between languages with high fidelity. If this turns out to be true, we may be able to decode ancient texts such as Linear A or convert whale speech back to a human language. Only time will tell.
Thanks for reading Token for Token! Subscribe for free to receive new posts and support my work.
At the start of the 2024/25 university year, KPMG released an article suggesting students that use AI say they aren’t learning as much. The article suggest 59% of Canadian students use AI for their schoolwork, which should have alarm bells ringing on every front. I mean everyone was scared that Wikipedia would ruin education, but students still had to find things, now they don’t even need to do that, because AI will. Two thirds admit they are not learning or retaining as much knowledge. Yeah, go figure. Is anyone really surprised?
What are they using it for? The article suggests 46% are using it to generate ideas, and 41% to do research. Wait, generate ideas – isn’t that the whole point of university, further developing thinking abilities? 75% of students say it has improved the quality of their schoolwork – yeah, because they aren’t doing it, AI is. How are you suppose to get better at something if you never fail? By letting AI improve your work, you aren’t actually building any skills.
There are a whole lot more stats in the article, but the one that stands out is that 65% say “they feel that they are cheating when they use generative AI”. Yes, because you are cheating. Look it’s one thing to have AI help with reviewing an assignment, but generating ideas? Even research is iffy – that’s what university is suppose to do, teach you how to do research. What happens if AI doesn’t have the complete picture to answer a question? There are a lot of historic documents that aren’t digitized, how do you account for the information they contain? How about field work, will AI do that for you too?
Why are these students even at university? In most jobs you get paid to think. If you’re using AI, then you may as well be replaced by AI. A 2024 UK survey paints an even bleaker picture. There 92% of students are using AI in one form or another. Why are they using AI, well to ‘save time and improve the quality of their work’. Again dah. But it’s AI doing the work, so maybe it should get the degree?
It’s time to reboot higher education. Yes, there is undoubtedly a place for AI in things like research, grammar etc – but there is no place for it replacing the human brains that are suppose to be learning something. But then again, maybe all is already lost. AI is probably already helping people get degrees who don’t even have a grasp of ‘basic’ English.
When leaders start treating higher education institutions like the learning establishments they should be instead of the mills they are, then perhaps change can occur. Until then, we will just relish the rise of the ‘human’ machines.
AI leaders have predicted that it will enable dramatic scientific progress: curing cancer, doubling the human lifespan, colonizing space, and achieving a century of progress in the next decade. Given the cuts to federal funding for science in the U.S., the timing seems perfect, as AI could replace the need for a large scientific workforce.
It’s a common-sense view, at least among technologists, that AI will speed science greatly as it gets adopted in every part of the scientific pipeline — summarizing existing literature, generating new ideas, performing data analyses and experiments to test them, writing up findings, and performing “peer” review.
But many early common-sense predictions about the impact of a new technology on an existing institution proved badly wrong. The Catholic Church welcomed the printing press as a way of solidifying its authority by printing Bibles. The early days of social media led to wide-eyed optimism about the spread of democracy worldwide following the Arab Spring.
Similarly, the impact of AI on science could be counterintuitive. Even if individual scientists benefit from adopting AI, it doesn’t mean science as a whole will benefit. When thinking about the macro effects, we are dealing with a complex system with emergent properties. That system behaves in surprising ways because it is not a market. It is better than markets at some things, like rewarding truth, but worse at others, such as reacting to technological shocks. So far, on balance, AI has been anunhealthyshock to science, stretching many of its processes to the breaking point.
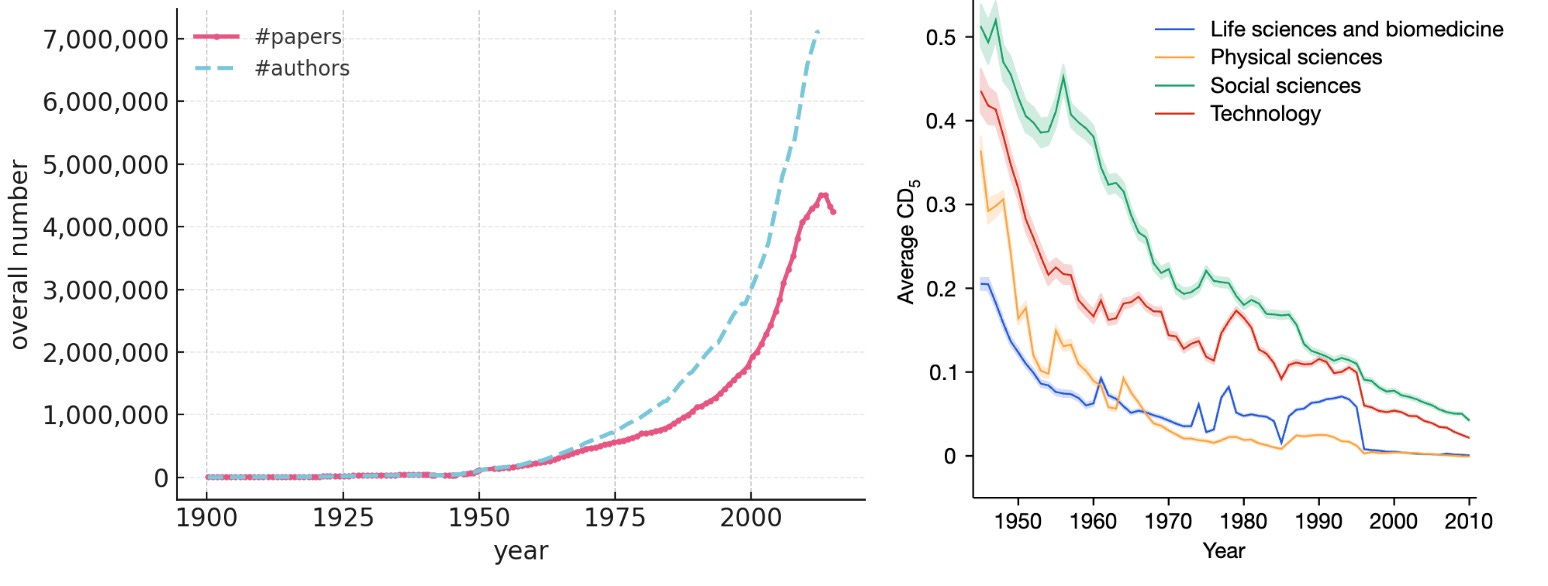
Any serious attempt to forecast the impact of AI on science must confront the production-progress paradox. The rate of publication of scientific papers has been growing exponentially, increasing 500 fold between 1900 and 2015. But actual progress, by any available measure, has been constant or even slowing. So we must ask how AI is impacting, and will impact, the factors that have led to this disconnect.
Our analysis in this essay suggests that AI is likely to worsen the gap. This may not be true in all scientific fields, and it is certainly not a foregone conclusion. By carefully and urgently taking actions such as those we suggest below, it may be possible to reverse course. Unfortunately, AI companies, science funders, and policy makers all seem oblivious to what the actual bottlenecks to scientific progress are. They are simply trying to accelerate production, which is like adding lanes to a highway when the slowdown is actually caused by a toll booth. It’s sure to make things worse.
Science has been slowing — the production-progress paradox
The total number of published papers is increasing exponentially, doubling every 12 years. The total number of researchers who have authored a research paper is increasing even more quickly. And between 2000 and 2021, investment in research and development increased fourfold across the top seven funders (the US, China, Japan, Germany, South Korea, the UK, and France).1
But does this mean faster progress? Not necessarily. Some papers lead to fundamental breakthroughs that change the trajectory of science, while others make minor improvements to known results.
Genuine progress results from breakthroughs in our understanding. For example, we understood plate tectonics in the middle of the last century — the idea that the continents move. Before that, geologists weren’t even able to ask the right questions. They tried to figure out the effects of the cooling of the Earth, believing that that’s what led to geological features such as mountains. No amount of findings or papers in older paradigms of geology would have led to the same progress that plate tectonics did.
So it is possible that the number of papers is increasing exponentially while progress is not increasing at the same rate, or is even slowing down. How can we tell if this is the case?
One challenge in answering this question is that, unlike the production of research, progress does not have clear, objective metrics. Fortunately, an entire research field — the "science of science", or metascience — is trying to answer this question. Metascience uses the scientific method to study scientific research. It tackles questions like: How often can studies be replicated? What influences the quality of a researcher's work? How do incentives in academia affect scientific outcomes? How do different funding models for science affect progress? And how quickly is progress really happening?
Left: The number of papers authored and authors of research papers have been increasing exponentially (from Dong et al., redrawn to linear scale using a web plot digitizer). Right: The disruptiveness of papers is declining over time (from Park et al.).
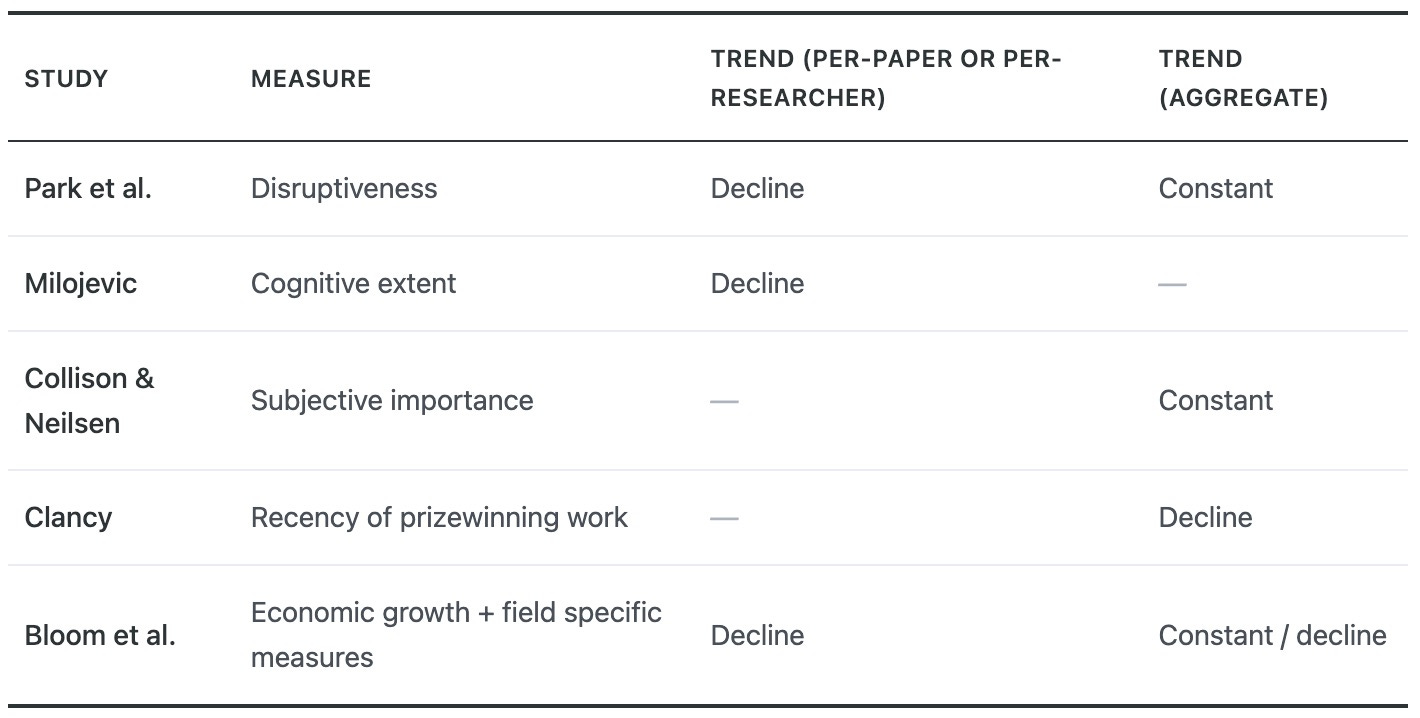
Strikingly, many findings from metascience suggest that progress has been slowing down, despite dramatic increases in funding, the number of papers published, and the number of people who author scientific papers. We collect some evidence below; Matt Clancy reviews many of these findings in much more depth.
1) Park et al. find that "disruptive" scientific work represents an ever-smaller fraction of total scientific output. Despite an exponential increase in the number of published papers and patents, the number of breakthroughs is roughly constant.
2) Research that introduces new ideas is more likely to coin new terms. Milojevic collects the number of unique phrases used in titles of scientific papers over time as a measure of the “cognitive extent” of science, and finds that while this metric increased up until the early 2000s, it has since entered a period of stagnation, when the number of unique phrases used in titles of research papers has gone down.
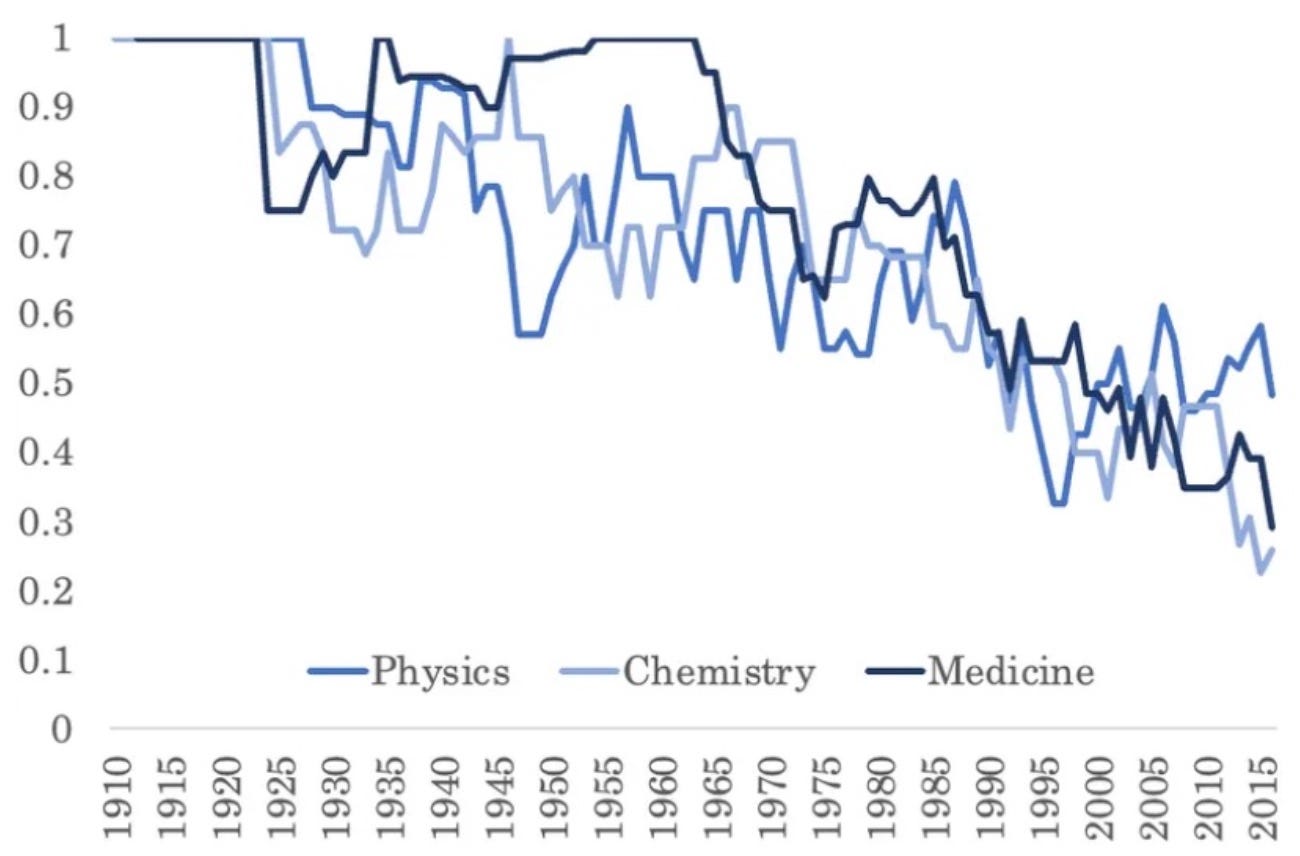
3) Patrick Collison and Michael Nielsen surveyed researchers across fields on how they perceived progress in the most important breakthroughs in their fields over time — those that won a Nobel prize. They asked scientists to compare Nobel-prize-winning research from the 1910s to the 1980s.
They found that scientists considered advances from earlier decades to be roughly as important as the ones from more recent decades, across Medicine, Physics, and Chemistry. Despite the vast increases in funding, published papers, and authors, the most important breakthroughs today are about as impressive as those in the decades past.
4) Matt Clancy complements this with an analysis of what fraction of discoveries that won a Nobel Prize in a given year were published in the preceding 20 years. He found that this number dropped from 90% in 1970 to 50% in 2015, suggesting that either transformative discoveries are happening at a slower pace, or that it takes longer for discoveries to be recognized as transformative.
Share of papers describing each year’s Nobel-prize winning work that were published in the preceding 20 years. 10-year moving average. Source: Clancy based on data from Li et al.
5) Bloom et al. analyze research output from an economic perspective. Assuming that economic growth ultimately comes from new ideas, the constant or declining rate of growth implies that the exponential increase in the number of researchers is being offset by a corresponding decline in the output per researcher. They find that this pattern holds true when drilling down into specific areas, including semiconductors, agriculture, and medicine (where the progress measures are Moore’s law, crop yield growth, and life expectancy, respectively).
The decline of research productivity. Note that economists use “production” as a catch-all term, with paper and patent counts, growth, and other metrics being different ways to measure it. We view production and progress as fundamentally different constructs, so we use the term production in a narrower sense. Keep in mind that in the figure, “productivity” isn’t based on paper production but on measures that are better viewed as progress measures. Source: Bloom et al.
Of course, there are shortcomings in each of the metrics above. This is to be expected: since progress doesn't have an objective metric, we need to rely on proxies for measuring it, and these proxies will inevitably have some flaws.
For example, Park et al. used citation patterns to flag papers as "disruptive": if follow-on citations to a given paper don't also cite the studies this paper cited, the paper is more likely to be considered disruptive. One criticism of the paper is that this could simply be a result of how citation practices have evolved over time, not a result of whether a paper is truly disruptive. And the metric does flag some breakthroughs as non-disruptive — for example, AlphaFold is not considered a disruptive paper by this metric.2
But taken together, the findings do suggest that scientific progress is slowing down, at least compared to the volume of papers, researchers, and resources. Still, this is an area where further research would be fruitful — while the decline in the pace of progress relative to inputs seems very clear, it is less clear what is happening at an aggregate level. Furthermore, there are many notions of what the goals of science are and what progress even means, and it is not clear how to connect the available progress measures to these higher-level definitions.
Summary of a few major lines of evidence of the slowdown in scientific progress
Why is progress slowing? Can AI help?
There are many hypotheses for why progress could be slowing. One set of hypotheses is that slowdown is an intrinsic feature of scientific progress, and is what we should expect. For example, there’s the low-hanging fruit hypothesis — the easy scientific questions have already been answered, so what remains to be discovered is getting harder.
This is an intuitively appealing idea. But we don’t find this convincing. Adam Mastroianni gives many compelling counter-arguments. He points out that we’ve been wrong about this over and over and lists many comically mis-timed assessments of scientific fields reaching saturation just before they ended up undergoing revolutions, such as physics in the 1890s.
While it’s true that lower-hanging fruits get picked first, there are countervailing factors. Over time, our scientific tools improve and we stand on the tower of past knowledge, making it easier to reach higher. Often, the benefits of improved tools and understanding are so transformative that whole new fields and subfields are created. New fields from the last 50-100 years include computer science, climate science, cognitive neuroscience, network science, genetics, molecular biology, and many others. Effectively, we’re plucking fruit from new trees, so there is always low-hanging fruit.
In our view, the low-hanging fruit hypothesis can at best partly explain slowdowns within fields. So it’s worth considering other ideas.
The second set of hypotheses is less fatalistic. They say that there’s something suboptimal about the way we’ve structured the practice of science, and so the efficiency of converting scientific inputs into progress is dropping. In particular, one subset of hypotheses flags the increase in the rate of production itself as the causal culprit — science is slowing down because it is trying to go too fast.
How could this be? The key is that any one scientist’s attention is finite, so they can only pay attention to a limited number of papers every year. So it is too risky for authors of papers to depart from the canon. Any such would-be breakthrough papers would be lost in the noise and won’t get the attention of a critical mass of scholars. The greater the rate of production, the more the noise, so the less attention truly novel papers will achieve, and thus will be less likely to break through into the canon.
when the number of papers published each year grows very large, the rapid flow of new papers can force scholarly attention to already well-cited papers and limit attention for less-established papers—even those with novel, useful, and potentially transformative ideas. Rather than causing faster turnover of field paradigms, a deluge of new publications entrenches top-cited papers, precluding new work from rising into the most-cited, commonly known canon of the field.
These arguments, supported by our empirical analysis, suggest that the scientific enterprise’s focus on quantity may obstruct fundamental progress. This detrimental effect will intensify as the annual mass of publications in each field continues to grow
Another causal mechanism relates to scientists’ publish-or-perish incentives. Production is easy to measure, and progress is hard to measure. So universities and other scientific institutions judge researchers based on measurable criteria such as how many papers they publish and the amount of grant funding they receive. It is not uncommon for scientists to have to publish a certain number of peer-reviewed papers to be hired or to get tenure (either due to implicit norms or explicit requirements).
The emphasis on production metrics seems to be worsening over time. Physics Nobel winner Peter Higgs famously noted that he wouldn't even have been able to get a job in modern academia because he wouldn't be considered productive enough.
So individual researchers' careers might be better off if they are risk averse, but it might reduce the collective rate of progress. Rzhetsky et al. find evidence of this phenomenon in biomedicine, where experiments tend to focus too much on experimenting with known molecules that are already considered important (which would be more likely to lead to publishing a paper) rather than more risky experiments that could lead to genuine breakthroughs. Worryingly, they find this phenomenon worsening over time.
This completes the feedback loop: career incentives lead to researchers publishing more papers, and disincentivize novel research that results in true breakthroughs (but might only result in a single paper after years of work).
If slower progress is indeed being caused by faster production, how will AI impact it? Most obviously, automating parts of the scientific process will make it even easier for scientists to chase meaningless productivity metrics. AI could make individual researchers more creative but decrease the creativity of the collective because of a homogenizing effect. AI could also exacerbate the inequality of attention and make it even harder for new ideas to break through. Existing search technology, such as Google Scholar, seems to be having exactly this effect.
To recap, so far we’ve argued that if the slowdown in science is caused by overproduction, AI will make it worse. In the next few sections, we’ll discuss why AI could worsen the slowdown regardless of what’s causing it.
Science is not ready for software, let alone AI
How do researchers use AI? In many ways: AI-based modeling to uncover trends in data using sophisticated pattern-matching algorithms; hand-written machine learning models specified based on expert knowledge; or even generative AI to write the code that researchers previously wrote. While some applications, such as using AI for literature review, don't involve writing code, most applications of AI for science are, in essence, software development.
Unfortunately, scientists are notoriously poor software engineers. Practices that are bog-standard in the industry, like automated testing, version control, and following programming design guidelines, are largely absent or haphazardly adopted in the research community. These are practices that were developed and standardized over the last six decades of software engineering to prevent bugs and ensure the software works as expected.
Worse, there is little scrutiny of the software used in scientific studies. While peer review is a long and arduous step in publishing a scientific paper, it does not involve reviewing the code accompanying the paper, even though most of the "science" in computational research is being carried out in the code and data accompanying a paper, and only summarized in the paper itself.
In fact, papers often fail to even share the code and data used to generate results, so even if other researchers are willing to review the code, they don't have the means to. Gabelica et al. found that of 1,800 biomedical papers that pledged to share their data and code, 93% did not end up sharing these artifacts. This even affects results in the most prominent scientific journals: Stodden et al. contacted the authors of 204 papers published in Science, one of the top scientific journals, to get the code and data for their study. Only 44% responded.
When researchers do share the code and data they used, it is often disastrously wrong. Even simple tools, like Excel, have notoriously led to widespread errors in various fields. A 2016 study found that one in five genetics papers suffer from Excel-related errors, for example, because the names of genes (say, Septin 2) were automatically converted to dates (September 2). Similarly, it took decades for most scientific communities to learn how to use simple statistics responsibly.
AI opens a whole new can of worms. The AI community often advertises AI as a silver bullet without realizing how difficult it is to detect subtle errors. Unfortunately, it takes much less competence to use AI tools than to understand them deeply and learn to identify errors. Like other software-based research, errors in AI-based science can take a long time to uncover. If the widespread adoption of AI leads to researchers spending more time and effort conducting or building on erroneous research, it could slow progress, since researcher time and effort are wasted in unproductive research directions.
Unfortunately, we've found that AI has already led to widespread errors. Even before generative AI, traditional machine learning led to errors in over 600 papers across 30 scientific fields. In many cases, the affected papers constituted the majority of the surveyed papers, raising the possibility that in many fields, the majority of AI-enabled research is flawed. Others have found that AI tools are often used with inappropriate baseline comparisons, making it incorrectly seem like they outperform older methods. These errors are not just theoretical: they affect the potential real-world deployment of AI too. For example, Roberts et al. found that of 400+ papers using AI for COVID-19 diagnosis, none produced clinically useful tools due to methodological flaws.
Applications of generative AI can result in new types of errors. For example, while AI can aid in programming, code generated using AI often has errors. As AI adoption increases, we will discover more applications of AI for science. We suspect we'll find widespread errors in many of these applications.
Why is the scientific community so far behind software engineering best practices? In engineering applications, bugs are readily visible through tests, or in the worst case, when they are deployed to customers. Companies have strong incentives to fix errors to maintain the quality of their applications, or else they will lose market share. As a result, there is a strong demand for software engineers with deep expertise in writing good software (and now, in using AI well). This is why software engineering practices in the industry are decades ahead of those in research. In contrast, there are few incentives to correct flawed scientific results, and errors often persist for years.
That is not to say science should switch from a norms-based to a market-based model. But it shouldn't be surprising that there are many problems markets have solved that science hasn't — such as developing training pipelines for software engineers. Where such gaps between science and the industry emerge, scientific institutions need to intentionally adopt industry best practices to ensure science continues to innovate, without losing what makes science special.
In short, science needs to catch up to a half century of software engineering — fast. Otherwise, its embrace of AI will lead to an avalanche of errors and create headwinds, not tailwinds for progress.
AI could help too. There are many applications of AI to spot errors. For example, the Black Spatula project and the YesNoError project use AI to uncover flaws in research papers. In our own work, we've developed benchmarks aiming to spur the development of AI agents that automatically reproduce papers. Given the utility of generative AI for writing code, AI itself could be used to improve researchers' software engineering practices, such as by providing feedback, suggestions, best practices, and code reviews at scale. If such tools become reliable and see widespread adoption, AI could be part of the solution by helping avoid wasted time and effort building on erroneous work. But all of these possibilities require interventions from journals, institutions, and funding agencies to incentivize training, synthesis, and error detection rather than production alone.
AI might prolong the reliance on flawed theories
One of the main uses of AI for science is modeling. Older modeling techniques required coming up with a hypothesis for how the world works, then using statistical models to make inferences about this hypothesis.
In contrast, AI-based modeling treats this process as a black box. Instead of making a hypothesis about the world and improving our understanding based on the model's results, it simply tries to improve our ability to predict what outcomes would occur based on past data.
Leo Breiman illustrated the differences between these two modeling approaches in his landmark paper "Statistical Modeling: The Two Cultures". He strongly advocated for AI-based modeling, often on the basis of his experience in the industry. A focus on predictive accuracy is no doubt helpful in the industry. But it could hinder progress in science, where understanding is crucial.
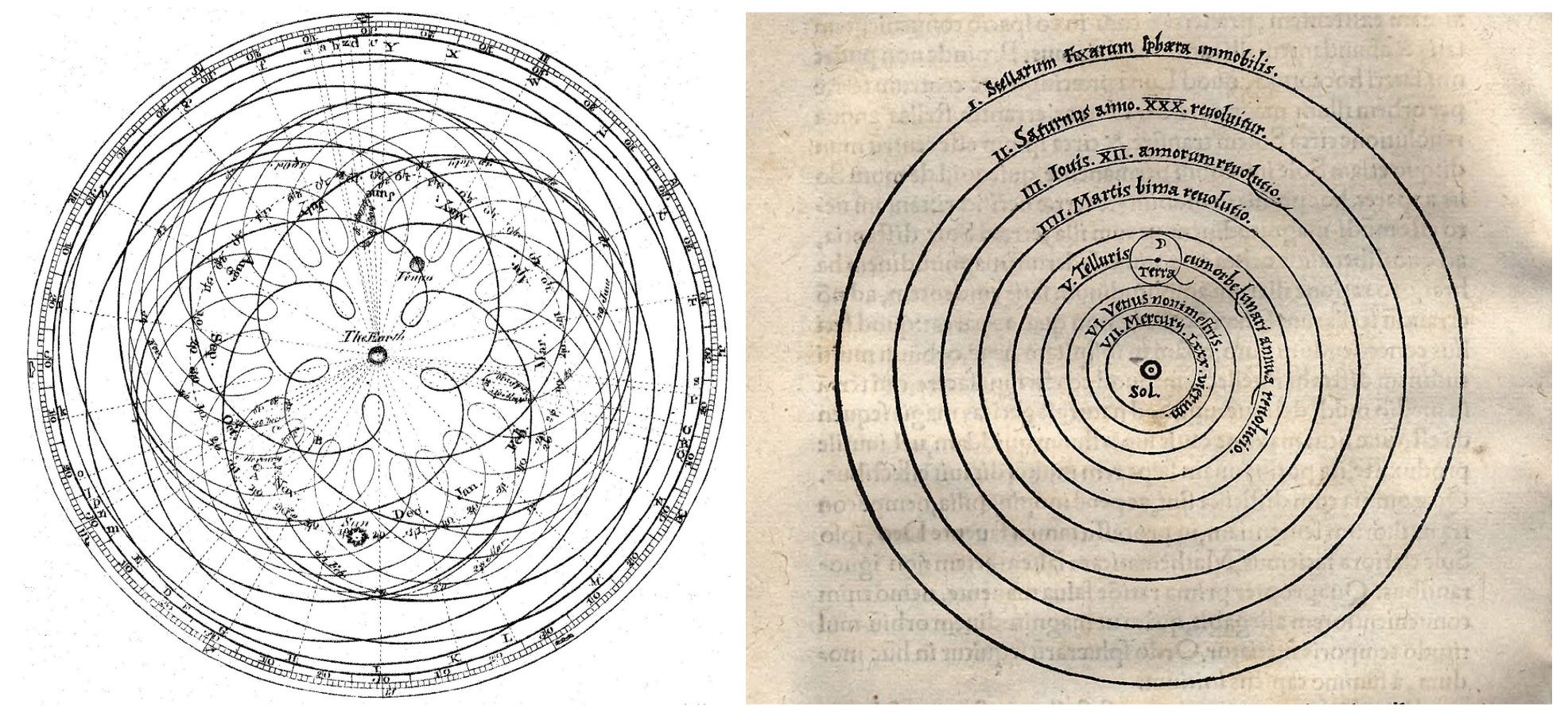
Why? In a recent commentary in the journal Nature, we illustrated this with an analogy to the geocentric model of the Universe in astronomy. The geocentric model of the Universe—the model of the Universe with the Earth at the center—was very accurate at predicting the motion of planets. Workarounds like "epicycles" made these predictions accurate. (Epicycles were the small circles added to the planet's trajectory around the Earth).
Whenever a discrepancy between the model's predictions and the experimental readings was observed, astronomers added an epicycle to improve the model's accuracy. The geocentric model was so accurate at predicting planets' motions that many modern planetariums still use it to compute planets' trajectories.
Left: The geocentric model of the Universe eventually became extremely complex due to the large number of epicycles. Right: The heliocentric model was far simpler.
How was the geocentric model of the Universe overturned in favor of the heliocentric model — the model with the planets revolving around the Sun? It couldn't be resolved by comparing the accuracy of the two models, since the accuracy of the models was similar. Rather, it was because the heliocentric model offered a far simpler explanation for the motion of planets. In other words, advancing from geocentrism to heliocentrism required a theoretical advance, rather than simply relying on the more accurate model.
This example shows that scientific progress depends on advances in theory. No amount of improvements in predictive accuracy could get us to the heliocentric model of the world without updating the theory of how planets move.
Let's come back to AI for science. AI-based modeling is no doubt helpful in improving predictive accuracy. But it doesn't lend itself to an improved understanding of these phenomena. AI might be fantastic at producing the equivalents of epicycles across fields, leading to the prediction-explanation fallacy.
In other words, if AI allows us to make better predictions from incorrect theories, it might slow down scientific progress if this results in researchers using flawed theories for longer. In the extreme case, fields would be stuck in an intellectual rut even as they excel at improving predictive accuracy within existing paradigms.
Could advances in AI help overcome this limitation? Maybe, but not without radical changes to modeling approaches and technology, and there is little incentive for the AI industry to innovate on this front. So far, improvements in predictive accuracy have greatly outpaced improvements in the ability to model the underlying phenomena accurately.
Prediction without understanding: Vafa et al. show that a transformer model trained on 10 million planetary orbits excels at predicting orbits without figuring out the underlying gravitational laws that produce those orbits.
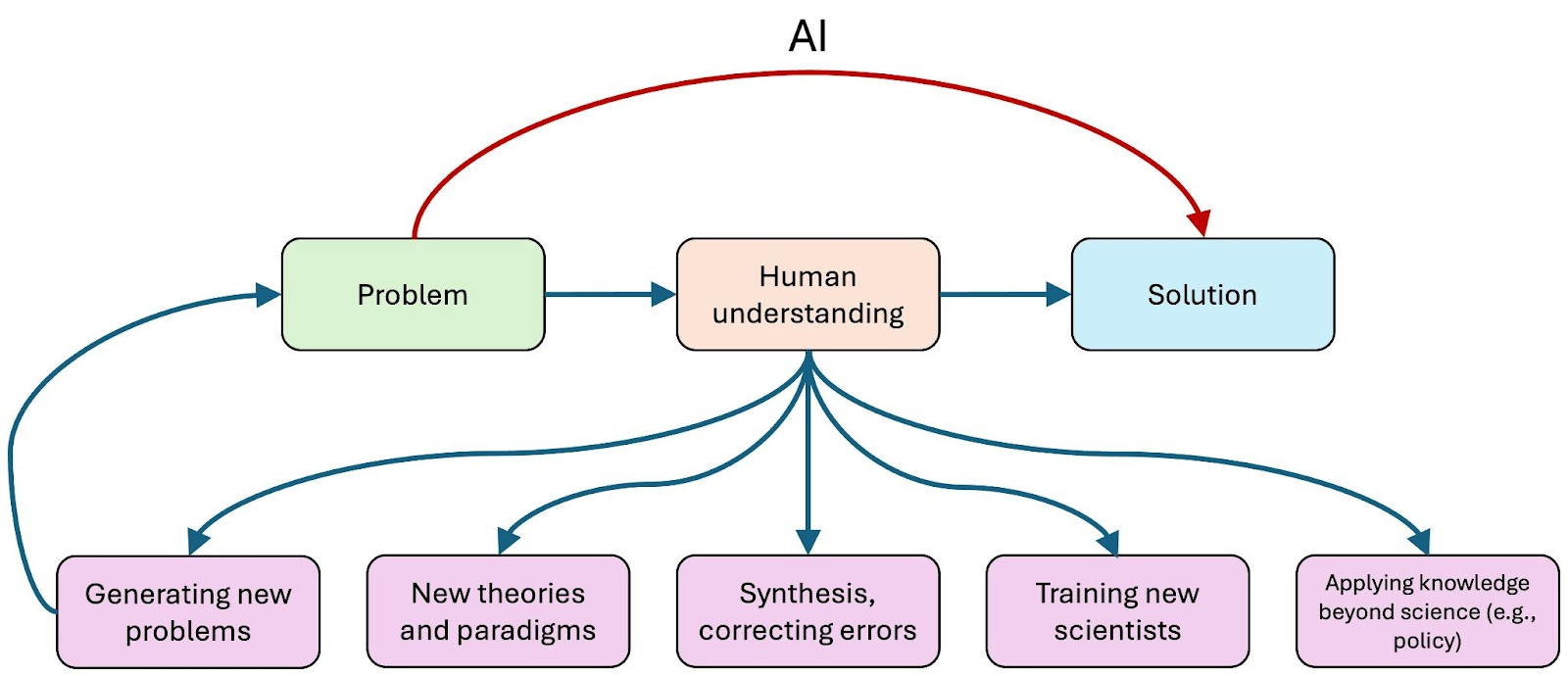
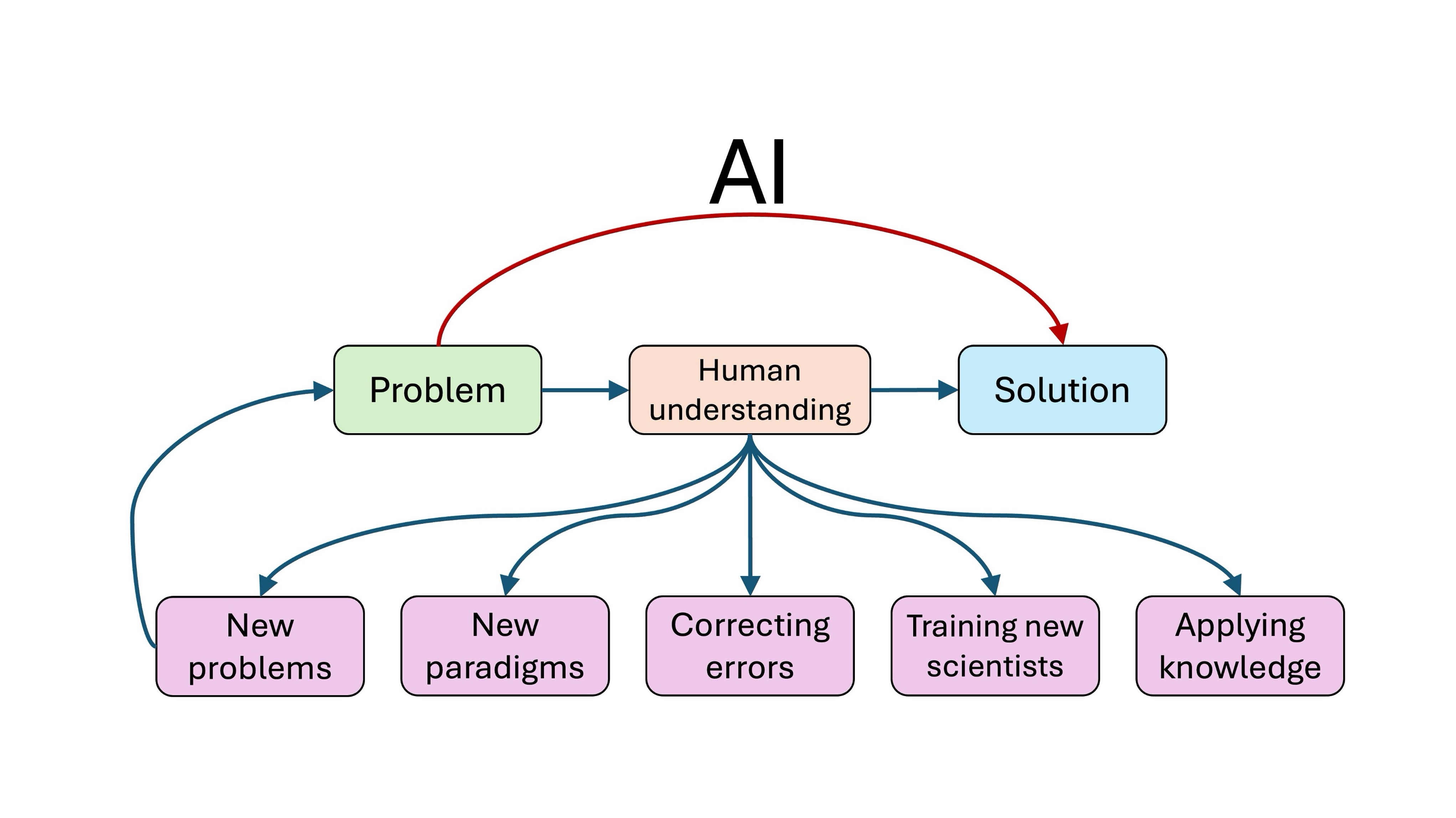
Human understanding remains essential
In solving scientific problems, scientists build up an understanding of the phenomena they study. It might seem like this understanding is just a way to get to the solution. So if we can automate the process of going from problem to solution, we don’t need the intermediate step.
The reality is closer to the opposite. Solving problems and writing papers about them can be seen as a ritual that leads to the real prize, human understanding, without which there can be no scientific progress.
Fields Medal-winning mathematician William Thurston wrote an essay brilliantly illustrating this. At the outset, he emphasizes that the point of mathematics is not simply to figure out the truth value for mathematical facts, but rather the accompanying human understanding:
…what [mathematicians] are doing is finding ways for people to understand and think about mathematics.
The rapid advance of computers has helped dramatize this point, because computers and people are very different. For instance, when Appel and Haken completed a proof of the 4-color map theorem using a massive automatic computation, it evoked much controversy. I interpret the controversy as having little to do with doubt people had as to the veracity of the theorem or the correctness of the proof. Rather, it reflected a continuing desire for human understanding of a proof, in addition to knowledge that the theorem is true.
On a more everyday level, it is common for people first starting to grapple with computers to make large-scale computations of things they might have done on a smaller scale by hand. They might print out a table of the first 10,000 primes, only to find that their printout isn't something they really wanted after all. They discover by this kind of experience that what they really want is usually not some collection of "answers"—what they want is understanding. [emphasis in original]
He then describes his experience as a graduate student working on the theory of foliations, a center of attention among many mathematicians. After he proved a number of papers on the most important theorems in the field, counterintuitively, people began to leave the field:
I heard from a number of mathematicians that they were giving or receiving advice not to go into foliations—they were saying that Thurston was cleaning it out. People told me (not as a complaint, but as a compliment) that I was killing the field. Graduate students stopped studying foliations, and fairly soon, I turned to other interests as well.
I do not think that the evacuation occurred because the territory was intellectually exhausted—there were (and still are) many interesting questions that remain and that are probably approachable. Since those years, there have been interesting developments carried out by the few people who stayed in the field or who entered the field, and there have also been important developments in neighboring areas that I think would have been much accelerated had mathematicians continued to pursue foliation theory vigorously.
Today, I think there are few mathematicians who understand anything approaching the state of the art of foliations as it lived at that time, although there are some parts of the theory of foliations, including developments since that time, that are still thriving.
Two things led to this desertion. First, the results he documented were written in a way that was hard to understand. This discouraged newcomers from entering the field. Second, even though the point of mathematics is building up human understanding, the way mathematicians typically get credit for their work is by proving theorems. If the most prominent results in a field have already been proven, that leaves few incentives for others to understand a field's contributions, because they can't prove further results (which would ultimately lead to getting credit).
In other words, researchers are incentivized to prove theorems. More generally, researchers across fields are incentivized to find solutions to scientific problems. But this incentive only leads to progress because the process of proving theorems or finding solutions to problems also leads to building human understanding. As the desertion of work on foliations shows, when there is a mismatch between finding solutions to problems and building human understanding, it can result in slower progress.
This is precisely the effect AI might have: by solving open research problems without leading to the accompanying understanding, AI could erode these useful byproducts by reducing incentives to build understanding. If we use AI to short circuit this process of understanding, that is like using a forklift at the gym. You can lift heavier weights with it, sure, but that's not why you go to the gym.
AI could short circuit the process of building human understanding, which is essential to scientific progress
Of course, mathematics might be an extreme case, because human understanding is the end goal of (pure) mathematics, not simply knowing the truth value of mathematical statements. This might not be the case for many applications of science, where the end goal is to make progress towards a real-world outcome rather than human understanding, say, weather forecasting or materials synthesis.
Most fields lie in between these two extremes. If we use AI to bypass human understanding, or worse, retain only illusions of understanding, we might lose the ability to train new scientists, develop new theories and paradigms, synthesize and correct results, apply knowledge beyond science, or even generate new and interesting problems.
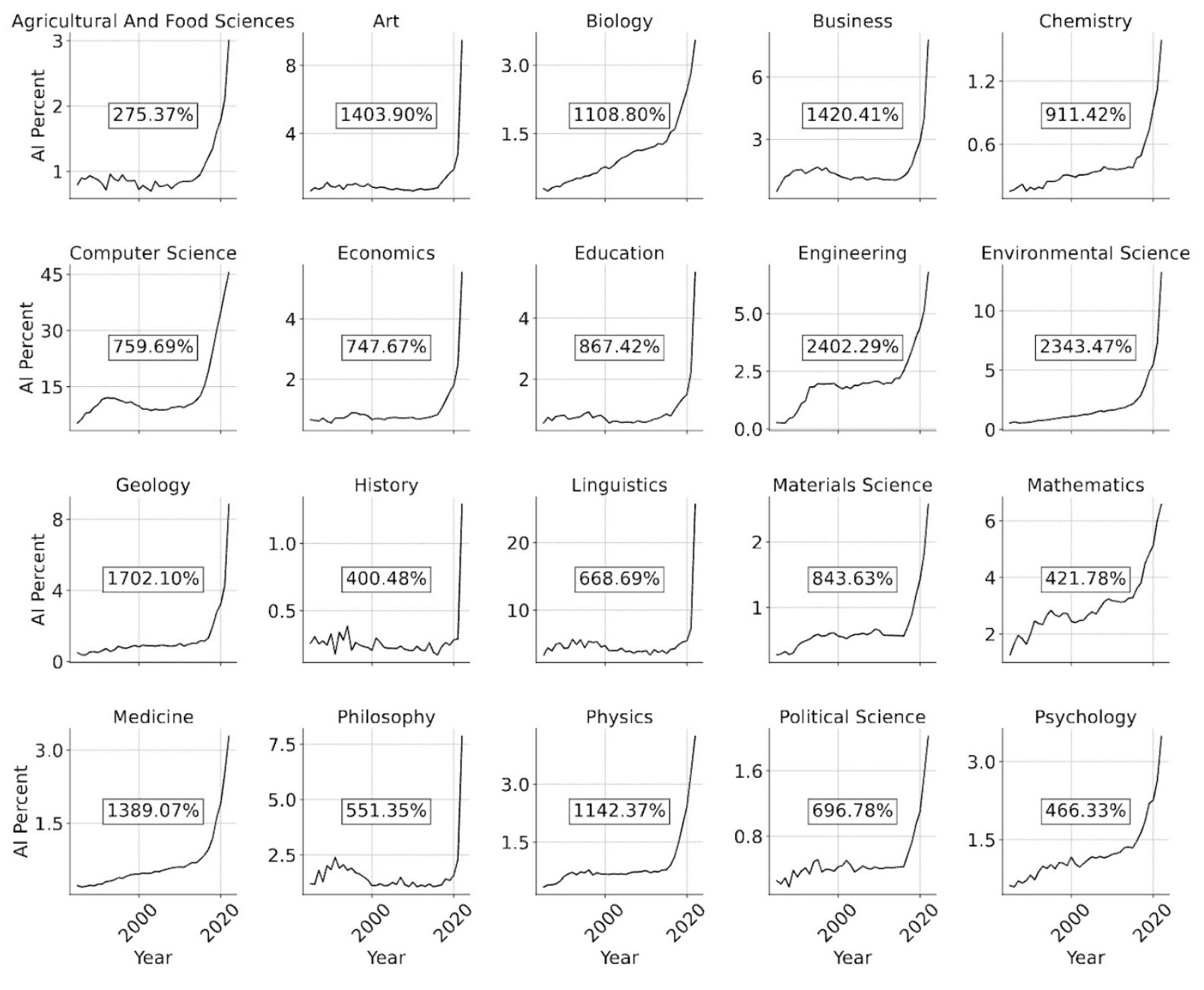
Empirical evidence across scientific fields has found evidence for some of these effects. For example, Hao et al. collect data from six fields and find that papers that adopt AI are more likely to focus on providing solutions to known problems and working within existing paradigms rather than generating new problems.
Of course, AI can also be used to build up tacit knowledge, such as by helping people understand mathematical proofs or other scientific knowledge. But this requires fundamental changes to how science is organized. Today's career incentives and social norms prize solutions to scientific problems over human understanding. As AI adoption accelerates, we need changes to incentives to make sure human understanding is prioritized.
Implications for the future of science
Over the last decade, scientists have been in a headlong rush to adopt AI. The speed has come at the expense of any ability to adapt slow-moving scientific institutional norms to maintain quality control and identify and preserve what is essentially human about science. As a result, the trend is likely to worsen the production-progress paradox, accelerating paper publishing but only digging us deeper into the hole with regard to true scientific progress.
The number of papers that use AI quadrupled across 20 fields between 2012 and 2022 — even before the adoption of large language models. Figure by Duede et al.
So, what should the scientific community do differently? Let’s talk about the role of individual researchers, funders, publishers and other gatekeepers, and AI companies.
Changing scientific practices
Individual researchers should be more careful when adopting AI. They should build software engineering skills, learn how to avoid a long and growing list of pitfalls in AI-based modeling, and ensure they don’t lose their expertise by using AI as a crutch or an oracle. Sloppy use of AI may help in the short run, but will hinder meaningful scientific achievement.
With all that said, we recognize that most individual researchers are rationally following their incentives (productivity metrics). Yelling at them is not going to help that much, because what we have are collective action problems. The actors with real power to effect change are journals, universities hiring & promotion committees, funders, policymakers, etc. Let’s turn to those next.
Investing in meta-science
Meta-science research has been extremely valuable in revealing the production-progress paradox. But so far, that finding doesn’t have a lot of analytical precision. There’s only the fuzzy idea that science is getting less bang for its buck. This finding is generally consistent with scientists’ vibes, and is backed by a bunch of different metrics that vaguely try to measure true progress. But we don’t have a clear understanding of what the construct (progress) even is, and we’re far from a consensus story about what’s driving the slowdown.
To be clear, we will never have One True Progress Metric. If we did, Goodhardt/Campbell’s law would kick in — “When a measure becomes a target, it ceases to be a good measure.” Scientists would start to furiously optimize it, just as we have done with publication and citation counts, and the gaming would render it useless as a way to track progress.
That said, there’s clearly a long way for meta-science to go in improving both our quantitative and (more importantly) our qualitative/causal understanding of progress and the slowdown. Meta-science must also work to understand the efficacy of solutions.
Despiterecentgrowth, meta-science funding is a fraction of a percent of science funding (and research on the slowdown is only a fraction of that pie). If it is indeed true that science funding as a whole is getting orders of magnitude less bang for the buck than in the past, meta-science investment seems ruefully small.
Reforming incentives
Scientists constantly complain to each other about the publish-or-perish treadmill and are keenly aware that the production-focused reward structure isn’t great for incentivizing scientific progress. But efforts to change this have consistently failed. One reason is simple inertia. Then there’s the aforementioned Goodhart’s law — whatever new metric is instituted will quickly be gamed. A final difficulty is that true progress can only be identified retrospectively, on timescales that aren’t suitable for hiring and promotion decisions.
One silver lining is that as the cost of publishing papers further drops due to AI, it could force us to stop relying on production metrics. In the AI field itself, the effort required to write a paper is so low that we are heading towards a singularity, with some researchers being able to (co-)author close to 100 papers a year. (But, again, the perceived pace of actual progress seems mostly flat.) Other fields might start going the same route.
Rewarding the publication of individual findings may simply not be an option for much longer. Perhaps the kinds of papers that count toward career progress should be limited to things that are hard to automate, such as new theories or paradigms of scientific research. Any reforms to incentive structures should go hand-in-hand with shifts in funding.
One thing we don’t need is more incentives for AI adoption. As we explained above, it is already happening at breakneck speed, and is not the bottleneck.
Rethinking AI-for-science tools
When it comes to AI-for-science labs and tools that come from big AI companies, the elephant in the room is that their incentives are messed up. They want flashy “AI discovers X!” headlines so that they can sustain the narrative that AI will solve humanity’s problems, which buys them favorable policy treatment. We are not holding our breath for this to change.
We should be skeptical of AI-for-science news headlines. Many of them are greatly exaggerated. The results may fail to reproduce, or AI may be framed as the main character when it was in fact one tool among many.
If there are any AI-for-science tool developers out there who actually want to help, here’s our advice. Target the actual bottlenecks instead of building yet another literature review tool. How about tools for finding errors in scientific code or other forms of quality control? Listen to the users. For example, mathematicians have repeatedly said that tools for improving human understanding are much more exciting than trying to automate theorem-proving, which they view as missing the point.
The way we evaluate AI-for-science tools should also change. Consider a literature review tool. There are three kinds of questions one can ask: Does it save a researcher time and produce results of comparable quality to existing tools? How does the use of the tool impact the researcher’s understanding of the literature compared to traditional search? What will the collective impacts on the community be if the tool were widely adopted? For example, will everyone end up citing the same few papers?
Currently, only the first question is considered part of what evaluation means. The latter two are out of scope, and there aren’t even established methods or metrics for such measurement. That means that AI-for-science evaluation is guaranteed to provide a highly incomplete and biased picture of the usefulness of these tools and minimize their potential harms.
Final thoughts
We ourselves are enthusiastic users of AI in our scientific workflows. On a day-to-day basis, it all feels very exciting. That makes it easy to forget that the impact of AI on science as an institution, rather than individual scientists, is a different question that demands a different kind of analysis. Writing this essay required fighting our own intuitions in many cases. If you are a scientist who is similarly excited about using these tools, we urge you to keep this difference in mind.
Our skepticism here has similarities and differences to our reasons for the slow timelines we laid out in AI as Normal Technology. Market mechanisms exert some degree of quality control, and many shoddy AI deployments have failed badly, forcing companies who care about their reputation to take it slow when deploying AI, especially for consequential tasks, regardless of how fast the pace of development is. In science, adoption and quality control processes are decoupled, with the former being much faster.
We are optimistic that scientific norms and processes will catch up in the long run. But for now, it’s going to be a bumpy ride.
We are grateful to Eamon Duede for feedback on a draft of this essay.
Further reading
The American Science Acceleration Project (ASAP) is a national initiative with the stated goal of making American science "ten times faster by 2030". The offices of Senators Heinrich and Rounds recently requested feedback on how to achieve this. In our response, we emphasized the production-progress paradox, discussed why AI could slow (rather than hasten) scientific progress, and recommended policy interventions that could help.
Our colleague Alondra Nelson also wrote a response to the ASAP initiative, emphasizing that faster science is not automatically better, and highlighted many challenges that remain despite increasing the pace of production.
In a recent commentary in the journal Nature, we discussed why the proliferation of AI-driven modeling could be bad for science.
We have written about the use of AI for science in many previous essays in this newsletter:
Lisa Messeri and Molly Crockett offer a taxonomy of the uses of AI in science. They discuss many pitfalls of adopting AI in science, arguing we could end up producing more while understanding less.
Matt Clancy reviewed the evidence for slowdowns in science and innovation, and discussed interventions for incentivizing genuine progress.
The Institute for Progress released a podcast series on meta-science. Among other things, the series discusses concerns about slowdown and alternative models for funding and organizing science.
This article in Nature News, published two years after the original study, documents the controversy surrounding the paper's results and responses from the authors.
Have you ever argued with someone who is seriously good at debating? I have. It sucks.
You’re constantly thrown off-balance, responding to a point you didn’t expect to. You find yourself defending the weak edges of your argument, while the main thrust gets left behind in the back-and-forth, and you end up losing momentum, confidence, and ultimately, the argument.
One of my close friends won international debate competitions for fun while we were at university (he’s now a successful criminal barrister), and he told me that the only trick in the book, once you boil it all down, is to make sure the conversation is framed in your terms. Once that happens, it’s all over bar the shouting.
For web users, 1998 was all about which portal you frequented. Was it Yahoo! with its massive directory of links (and partnership with the search engine AltaVista)? Was it the browser company portals, MSN or Netcenter? Was it the VC-funded Excite or Lycos? All of them wanted your eyeballs and ran terrible adverts on tv to get them.
Web business was booming, but it was also becoming obvious which companies were winning and which were losing. Microsoft's Internet Explorer browser continued to drain users from Netscape, forcing the younger company to make a drastic move: open source its technology. Meanwhile, an ambitious e-tailer named Amazon.com expanded beyond books in 1998 — bad news for its competitors.
Dot-com fever continued apace, with GeoCities (August) and eBay (September) among the high-profile IPOs in 1998. Not to mention a little company called Google starting in September.
GeoCities, July 1998 (the month before the company's IPO).
The State of Web Design
By 1998, web design had achieved a harmony of form and function, after the widely varying experiments of 1997.
In January 1998, Wired's head of design Jeffrey Veen presented his web design manifesto. "Today’s Web is slipping into a proprietary world of competing technologies, and only by understanding this dilemma at its core can those creating content come out ahead," he wrote, referencing the browser incompatibilities of Netscape Navigator and Microsoft's IE.
Veen's manifesto could be summed up with the maxim "form follows function," meaning that a website must have a structure (function) before presentation is applied (form).
Veen also emphasized the importance of simplicity. He likened web design to designing children's toys:
"Simple, bright, playful - the Web has a different aesthetic than most other media does, but it is similar, surprisingly, to that of children's toys. Both design aesthetics come from forms of limited bandwidth..."
Webmonkey CSS Quick Reference Guide, 1998; via Chris Casciano on Flickr.
As the web platform matured over 1998 — CSS 2, XML and DOM all got finalised in standards bodies this year — web design began to achieve the sophistication that designers like Veen and his contemporary Jeffrey Zeldman craved.
The Browser War is Won
If web design was reaching an equilibrium in 1998, the same couldn't be said about the contest between Netscape and Microsoft for browser supremacy. There would only be one winner.
On January 22, 1998, Netscape announced its “bold plans to make the source code for the next generation of its highly popular Netscape Communicator client software available for free licensing on the Internet.” This was the beginnings of Mozilla, a non-profit organisation that was unveiled at the end of March 1998.
It was a desparate — yet ultimately savvy — move by Netscape to open source not only its browser, but its suite of online products connected to the browser (email, calendar, etc.). It was fast losing ground to Microsoft, whose Internet Explorer browser was now pre-installed on the world’s dominant OS: Windows.
Not that Microsoft had everything go its way in 1998. In May, the Department of Justice and 20 states sued the company for bundling IE with Windows. The antitrust trial opened in October.
By the end of the year, Netscape had been sold to AOL — Microsoft had won the war. But at least Mozilla emerged from the ashes.
A printout of AOL's homepage on the day it acquired Netscape; via Joe Loong on Flickr.
Web Developers Fight Back
Meanwhile, web developers were becoming increasingly frustrated over 1998 at the empty promises of the browser companies. Both Netscape and Microsoft gave lip service to implementing standards, yet they continued to focus on their own proprietary features.
To fight back against browser incompatibilities, in August 1998 The Web Standards Project (which came to be known as WaSP) was launched by a group of independent web developers.
WaSP homepage, December 1998 (a Jeffrey Zeldman design); via Wayback Machine.
The WaSP group was concerned that the beta versions of Netscape’s Navigator 4.5 and Microsoft’s Internet Explorer 5.0 were “adding more proprietary enhancements without providing complete support for existing standards.” It also called out the “patchwork support” for the DOM — the Document Object Model, a method of programmatically interacting with a web page — in these upcoming browsers.
Although these problems weren't immediately solved, WaSP’s mix of advocacy and public shaming over the coming years would help ensure that web standards eventually won out.
Amazon Expansion
In June 1998, Amazon branched out from books and began to sell CDs on its now expanding e-commerce website. As The New York Times reported on June 11, Amazon’s music catalog contained “more than 100,000 CD's, with 225,000 songs to sample using Real Audio.” The article mentioned that CDnow, Music Boulevard and Tower Records “are already far ahead of Amazon.” But given Amazon’s reputation for big spending, there was reason for those companies to be concerned. Amazon was just over a year old as a public company and had huge losses every quarter. But it was growing, fast.
Amazon.com, October 1998 — note the 'Music' tab; via NIST / Version Museum.
The following month, Amazon acquired two non-book companies: Junglee and Planet All. It was, said the Times in another article, “a move indicating that its aspirations extend to selling far more than books over the Internet.” The same report noted that Amazon.com had “grown to be the most successful merchant on the Internet, with 3.1 million customers.”
In October, with their stock prices tanking, CDnow and N2K merged — but it wouldn't matter, because Amazon had already won.
CNN Money illustration of CD e-tailer sharemarket trends, October 23, 1998.
Portals
“Portal” was, as Wired put it in a September profile of Excite, “the season's hot buzzword.” CEO George Bell defined a portal as “an efficient starting point that allows you to cut through the confusion of the Web and get to the information you want.”
Excite was engaged in a “land grab” to “become that starting point,” Bell said. The web at this time had a frontier mentality and so land grabbing was an increasingly common metaphor used by entrepreneurs. Fuelled by venture capital and IPOs, companies like Excite had a grow-at-all-costs strategy — with the hope that once they’d grabbed enough virtual land, they could then extract rent from its users. Excite’s goal, said Bell, was to “get big fast.”
Unfortunately for Excite, it struggled to keep up with the likes of Yahoo! and AOL. It eventually sold to a large cable ISP company called @Home Network in January 1999.
Search
During 1998, the leading names in search were either portals (Yahoo, Netscape, Excite) or search engines trying to turn themselves into portals (AltaVista, Infoseek, Lycos).
AltaVista was the most popular pure search engine of its time (not counting directories like Yahoo!). It had a destination site — for most of 1998 located at altavista.digital.com — but it also syndicated its search technology to partners like Yahoo and Netscape. So while many users visited AltaVista directly, a large proportion of search query volume came from its presence on these popular portals.
For much of the year, Google was merely an academic project. It gathered some attention, including from Danny Sullivan’s Search Engine Watch, but to break through Google had to become a company and move off Stanford's web servers. So on September 4, 1998, founders Larry Page and Sergey Brin filed for incorporation.
By the end of 1998, a "beta" website was up and running on google.com.
Google in December 1998.
Things would never be the same again in search, or on the web. AltaVista (now owned by Compaq) didn't yet know it, but 1998 was the peak year for portals. It was the end of an era — going forward, directories were out and search was in.














 Do you Yahoo!?; a
Do you Yahoo!?; a  GeoCities,
GeoCities,  HotWired, February 1998;
HotWired, February 1998;  Webmonkey CSS Quick Reference Guide, 1998; via Chris Casciano
Webmonkey CSS Quick Reference Guide, 1998; via Chris Casciano  Marc Andreessen announcing Mozilla,
Marc Andreessen announcing Mozilla,  A printout of AOL's homepage on the day it acquired Netscape; via Joe Loong
A printout of AOL's homepage on the day it acquired Netscape; via Joe Loong  WaSP homepage, December 1998 (a Jeffrey Zeldman design); via
WaSP homepage, December 1998 (a Jeffrey Zeldman design); via  Amazon.com, October 1998 — note the 'Music' tab; via
Amazon.com, October 1998 — note the 'Music' tab; via  CNN Money illustration of CD e-tailer sharemarket trends,
CNN Money illustration of CD e-tailer sharemarket trends,  Excite web portal,
Excite web portal,  DEC's AltaVista search engine,
DEC's AltaVista search engine,  Google in December 1998.
Google in December 1998.{kind=link}
{kind=link}